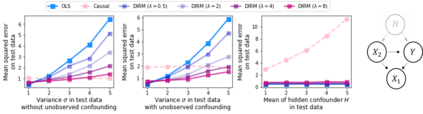
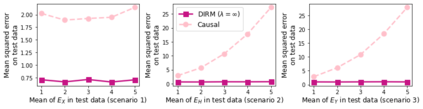
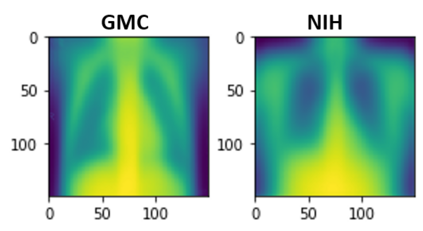
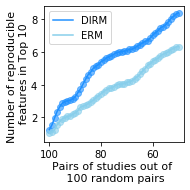
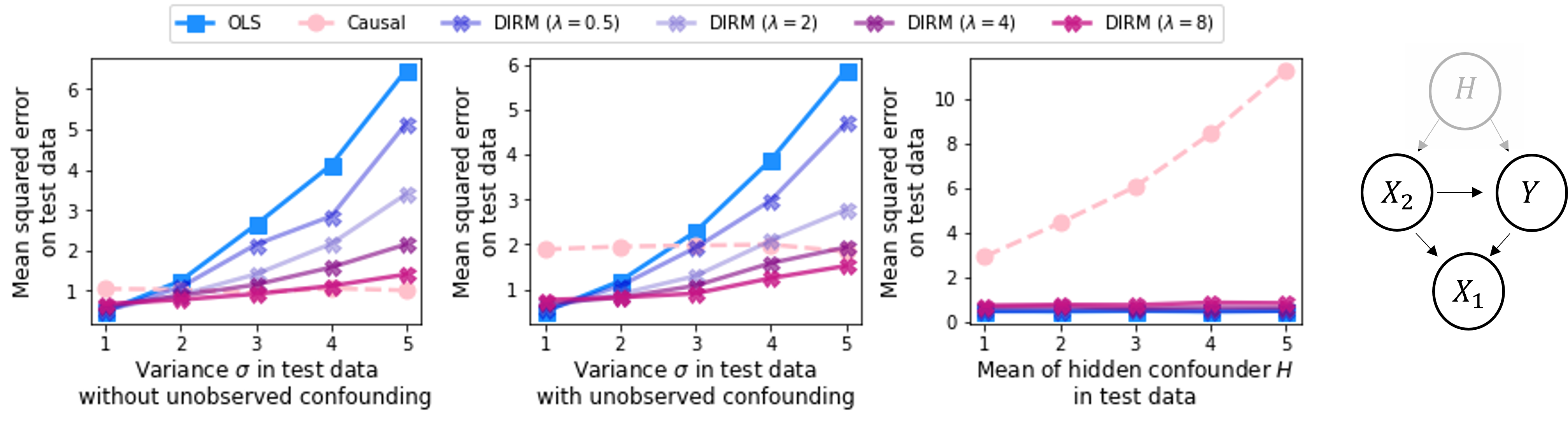
This paper investigates the problem of learning robust, generalizable prediction models from a combination of multiple datasets and qualitative assumptions about the underlying data-generating model. Part of the challenge of learning robust models lies in the influence of unobserved confounders that void many of the invariances and principles of minimum error presently used for this problem. Our approach is to define a different invariance property of causal solutions in the presence of unobserved confounders which, through a relaxation of this invariance, can be connected with an explicit distributionally robust optimization problem over a set of affine combination of data distributions. Concretely, our objective takes the form of a standard loss, plus a regularization term that encourages partial equality of error derivatives with respect to model parameters. We demonstrate the empirical performance of our approach on healthcare data from different modalities, including image, speech and tabular data.
翻译:本文探讨了从多种数据集和定性假设的组合中学习关于基本数据生成模型的可靠、可普遍适用的预测模型的问题,学习稳健模型的难题部分在于未观察到的困惑者的影响,这些影响使目前用于这一问题的许多最低误差的变数和原则变得无效。我们的方法是在未观察到的困惑者面前确定不同的因果解决方案的因果属性。 通过放松这种偏差,我们的目标可以与一系列数据分布的近似组合中明显的分配稳健优化问题相联系。具体地说,我们的目标采取标准损失的形式,加上一个鼓励在模型参数方面部分平等误差衍生物的正规化术语。我们展示了我们从不同模式(包括图像、语音和表格数据)出发的保健数据方法的经验性表现。