
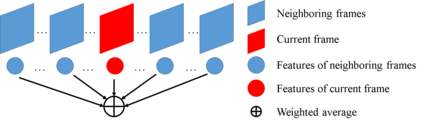
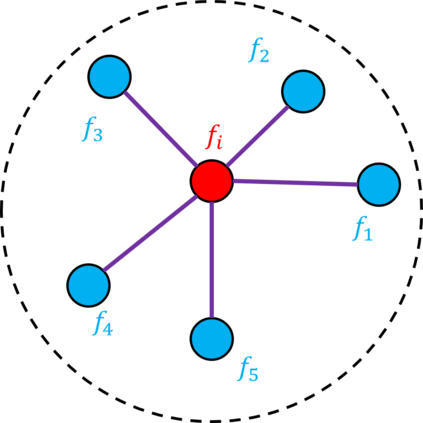
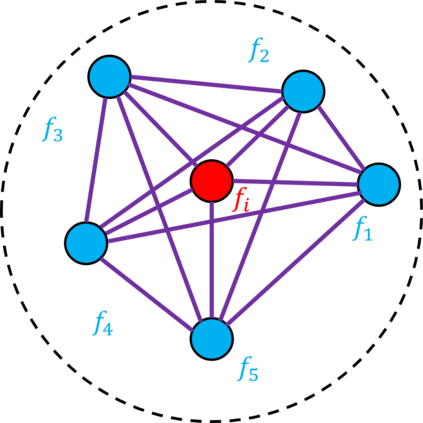
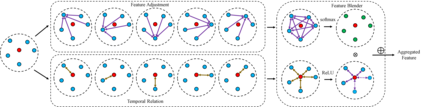
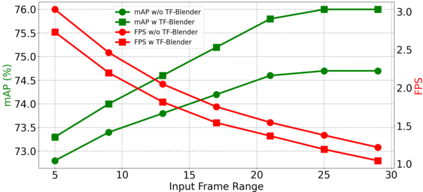
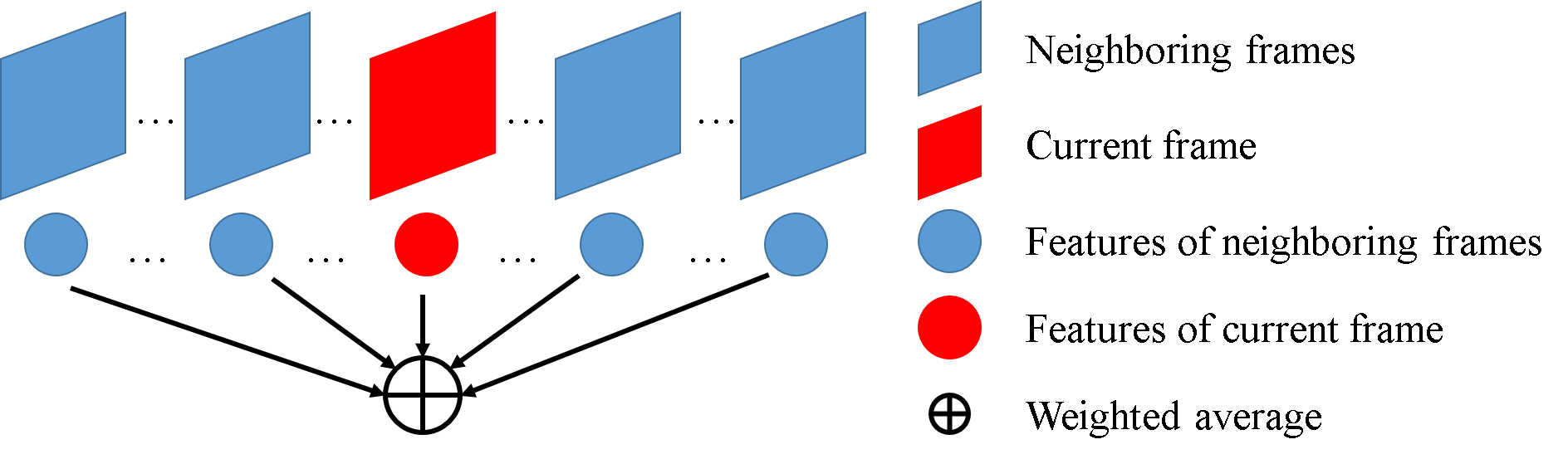
Video objection detection is a challenging task because isolated video frames may encounter appearance deterioration, which introduces great confusion for detection. One of the popular solutions is to exploit the temporal information and enhance per-frame representation through aggregating features from neighboring frames. Despite achieving improvements in detection, existing methods focus on the selection of higher-level video frames for aggregation rather than modeling lower-level temporal relations to increase the feature representation. To address this limitation, we propose a novel solution named TF-Blender,which includes three modules: 1) Temporal relation mod-els the relations between the current frame and its neighboring frames to preserve spatial information. 2). Feature adjustment enriches the representation of every neigh-boring feature map; 3) Feature blender combines outputs from the first two modules and produces stronger features for the later detection tasks. For its simplicity, TF-Blender can be effortlessly plugged into any detection network to improve detection behavior. Extensive evaluations on ImageNet VID and YouTube-VIS benchmarks indicate the performance guarantees of using TF-Blender on recent state-of-the-art methods.
翻译:由于孤立的视频框架可能会出现外观变形,这给探测工作带来极大的混乱,因此视频反对检测是一项具有挑战性的任务,因为孤立的视频框架可能会遇到外观变形,这给探测工作带来极大的混乱。流行的解决办法之一是利用时间信息,并通过集成相邻框架的特征来提高每个框架的代表性。尽管在探测方面有所改进,但现有方法侧重于选择高层次的视频框架进行聚合,而不是模拟较低层次的时间关系,以增加特征代表。为了应对这一限制,我们提议了一个名为TF-Blender的新解决方案,其中包括三个模块:(1) 时间关系模式将当前框架与其相邻框架之间的关系调整成模式,以保存空间信息。(2) 特性调整丰富了每个近光博特征图的代表性;(3) 特性混合器将前两个模块的输出合并起来,并为以后的检测任务产生更强的特征。为了简便,TF-Blender可以不费力地插入任何探测网络,以改进探测行为。对图像网VID和YouTube-VIS基准的广泛评价表明使用TF-Blander最近采用最先进的方法的绩效保障。



相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem

