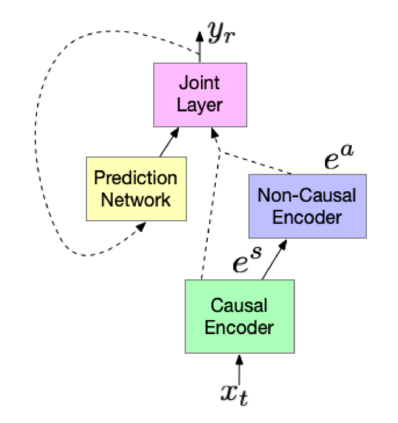
End-to-end (E2E) models have shown to outperform state-of-the-art conventional models for streaming speech recognition [1] across many dimensions, including quality (as measured by word error rate (WER)) and endpointer latency [2]. However, the model still tends to delay the predictions towards the end and thus has much higher partial latency compared to a conventional ASR model. To address this issue, we look at encouraging the E2E model to emit words early, through an algorithm called FastEmit [3]. Naturally, improving on latency results in a quality degradation. To address this, we explore replacing the LSTM layers in the encoder of our E2E model with Conformer layers [4], which has shown good improvements for ASR. Secondly, we also explore running a 2nd-pass beam search to improve quality. In order to ensure the 2nd-pass completes quickly, we explore non-causal Conformer layers that feed into the same 1st-pass RNN-T decoder, an algorithm called Cascaded Encoders [5]. Overall, we find that the Conformer RNN-T with Cascaded Encoders offers a better quality and latency tradeoff for streaming ASR.
翻译:终端到终端模式(E2E)已经显示,在多个层面,包括质量(以字差率(WER)衡量)和端点悬浮度[2]方面,超越了流出语音识别[1]的最先进的常规模式[1],包括质量(以字差率衡量)和端点延缓度[2]。然而,该模式仍然倾向于将预测延迟到终端,因此与常规的ASR模式相比,部分延缓度要高得多。为解决这一问题,我们考虑鼓励E2E模式通过一个称为FastEmit[3]的算法,尽早释放言词。自然,改进延缓度导致质量退化。为此,我们探索用Consect 层取代我们E2E模型编码中的LSTM层[4],这显示了ASR的良好改进。第二,我们还探索进行二次通波段搜索,以提高质量。为了确保第二通路快速完成,我们探索非二次连接的连接层层,以同样的1号 RNNE-T 解码,一种称为Cassed Enecters-endecersal 与Axent Regent Regent Regental 提供一个质量。