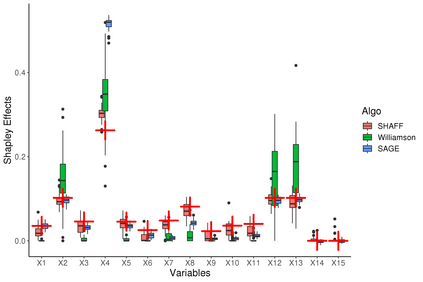
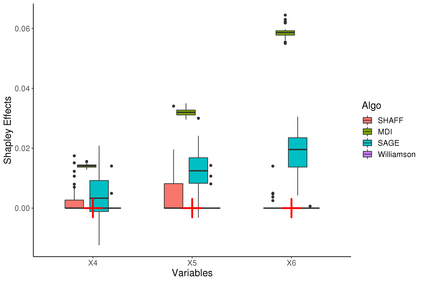
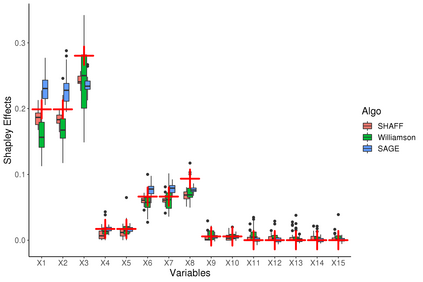
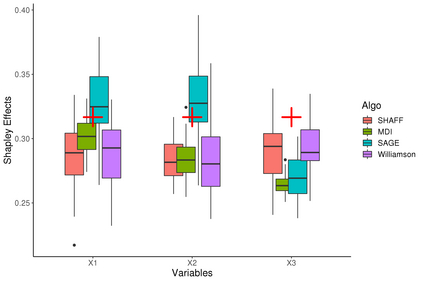
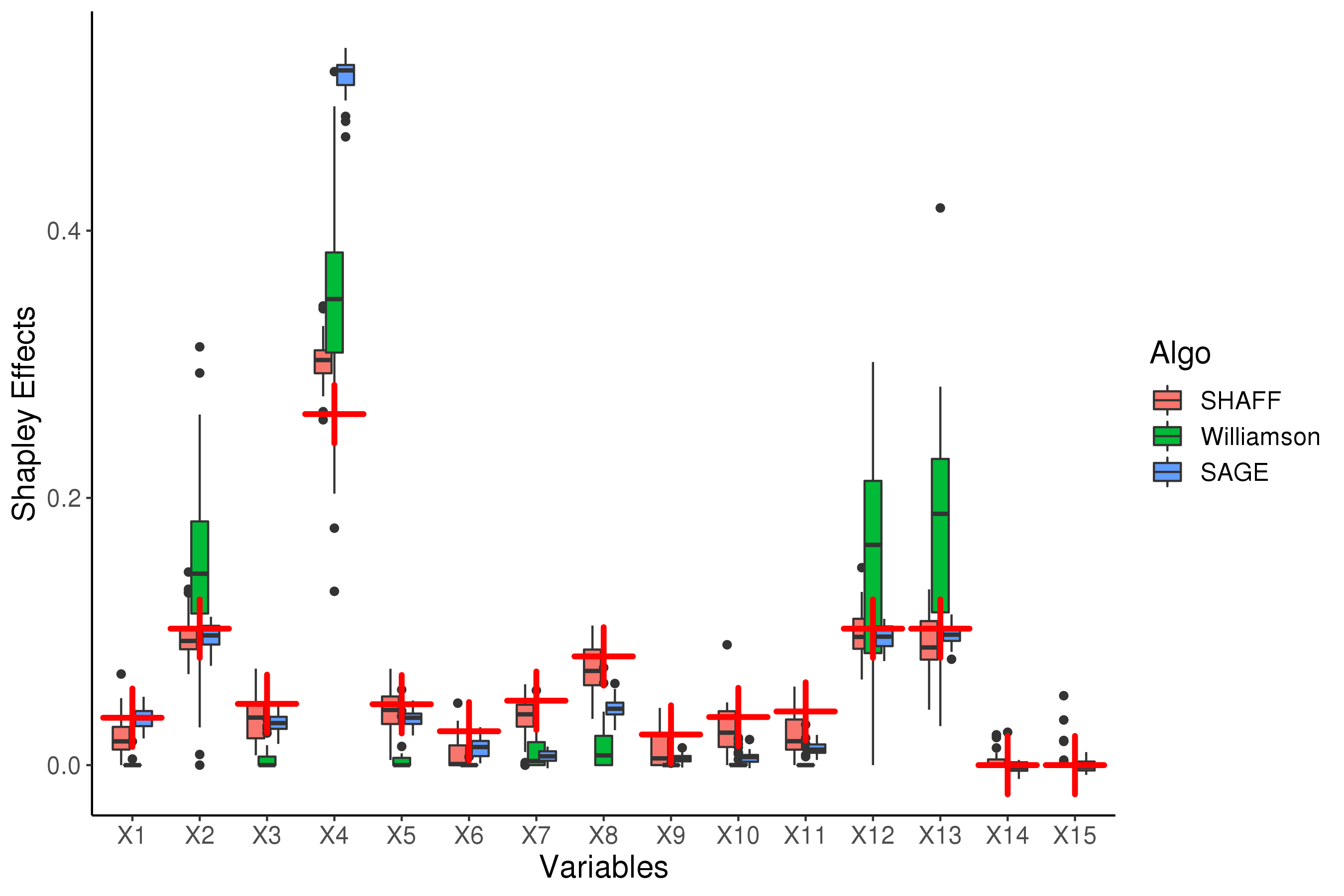
Interpretability of learning algorithms is crucial for applications involving critical decisions, and variable importance is one of the main interpretation tools. Shapley effects are now widely used to interpret both tree ensembles and neural networks, as they can efficiently handle dependence and interactions in the data, as opposed to most other variable importance measures. However, estimating Shapley effects is a challenging task, because of the computational complexity and the conditional expectation estimates. Accordingly, existing Shapley algorithms have flaws: a costly running time, or a bias when input variables are dependent. Therefore, we introduce SHAFF, SHApley eFfects via random Forests, a fast and accurate Shapley effect estimate, even when input variables are dependent. We show SHAFF efficiency through both a theoretical analysis of its consistency, and the practical performance improvements over competitors with extensive experiments. An implementation of SHAFF in C++ and R is available online.
翻译:学习算法的可解释性对于涉及关键决定的应用至关重要,可变重要性是主要解释工具之一。现在,对树群和神经网络的解释广泛使用沙粒效应,因为它们能够有效地处理数据中的依赖性和相互作用,而不是其他大多数可变重要性措施。然而,估计沙粒效应是一项艰巨的任务,因为计算的复杂性和有条件的预期估计。因此,现有的沙粒算法存在缺陷:运行时间昂贵,或者在投入变量依赖时存在偏差。因此,我们引入了SHAFF, 随机森林的SHAPley e Fefects, 快速和准确的沙粒效应估计,即使投入变量依赖。我们通过对其一致性进行理论分析,并通过广泛试验对竞争者的实际性能改进,展示SHAFF的效率。 SHAFF在C++和R中的实施可在网上查阅。