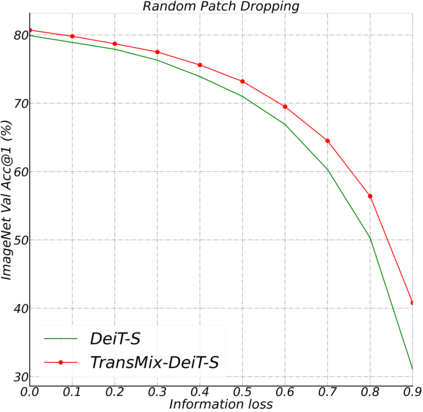
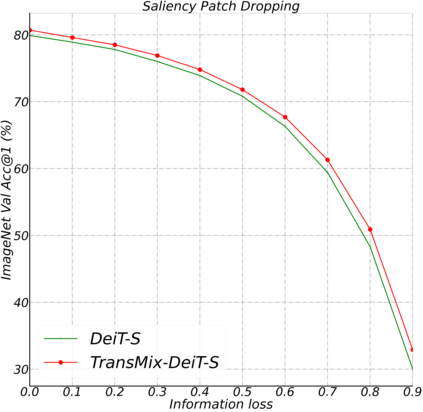
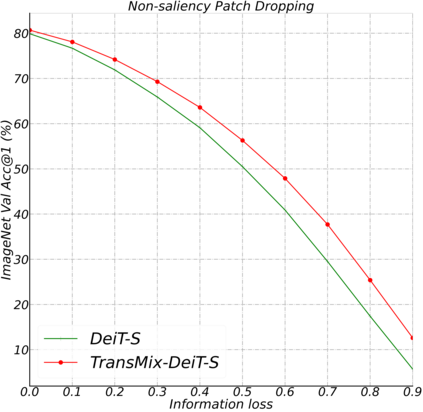
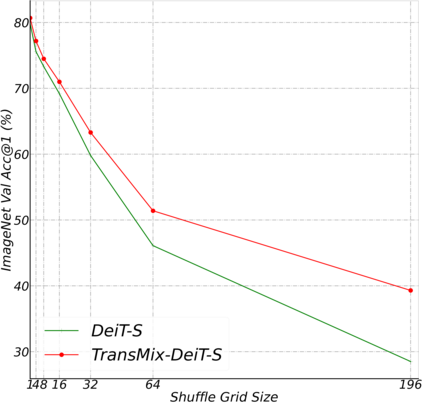
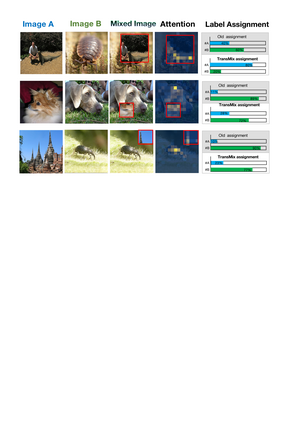
Mixup-based augmentation has been found to be effective for generalizing models during training, especially for Vision Transformers (ViTs) since they can easily overfit. However, previous mixup-based methods have an underlying prior knowledge that the linearly interpolated ratio of targets should be kept the same as the ratio proposed in input interpolation. This may lead to a strange phenomenon that sometimes there is no valid object in the mixed image due to the random process in augmentation but there is still response in the label space. To bridge such gap between the input and label spaces, we propose TransMix, which mixes labels based on the attention maps of Vision Transformers. The confidence of the label will be larger if the corresponding input image is weighted higher by the attention map. TransMix is embarrassingly simple and can be implemented in just a few lines of code without introducing any extra parameters and FLOPs to ViT-based models. Experimental results show that our method can consistently improve various ViT-based models at scales on ImageNet classification. After pre-trained with TransMix on ImageNet, the ViT-based models also demonstrate better transferability to semantic segmentation, object detection and instance segmentation. TransMix also exhibits to be more robust when evaluating on 4 different benchmarks. Code will be made publicly available at https://github.com/Beckschen/TransMix.
翻译:在培训期间,发现基于混合的增强功能对于推广模型是有效的,特别是对于愿景变换器(Vipple Greangers)而言,因为很容易过宽。然而,以往的基于混在一起的方法以前就有一个基本知识,即线性内插目标比应保持与输入内插中提议的比例相同。这可能导致一个奇怪的现象,即由于随机增强过程,混合图像中有时没有有效的对象,但在标签空间中仍然有反应。为了缩小输入和标签空间之间的这种差距,我们提议 TransMix,根据视野变换器的注意地图混合标签。如果相应的输入图像被关注图加权高,则标签的信心会更大。 TransMix简单易尴尬,可以在几行代码中执行,而不引入任何额外的参数和基于 ViT 模型的FLOPs。实验结果显示,我们的方法可以在图像网分类的尺度上不断改进基于ViT的各种模型。在对 TransMix进行预先训练后,基于 ViT-h的模型也会更有信心,如果相应的输入图像图像图像图像图像图像图像图像图像图像,那么的模型也会显示更可靠地显示M 4 Transmocils 。