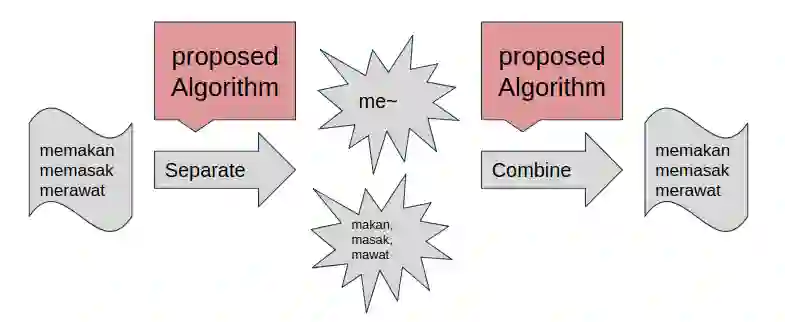
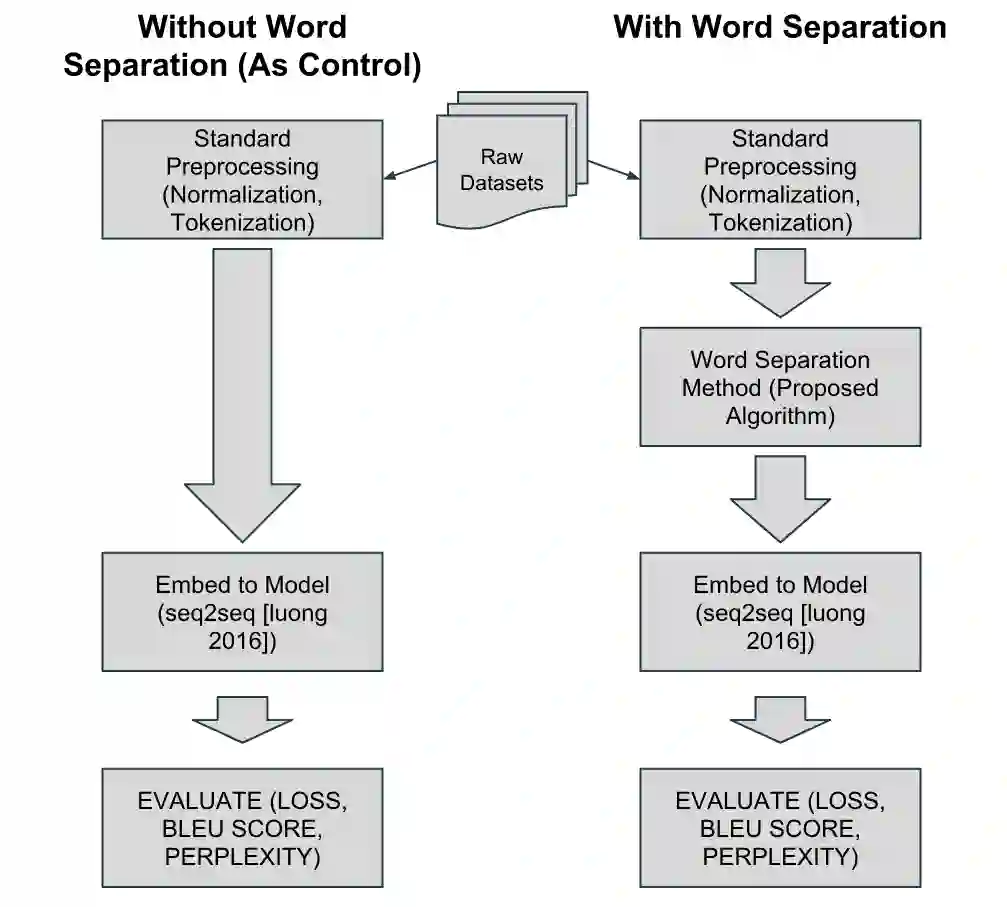
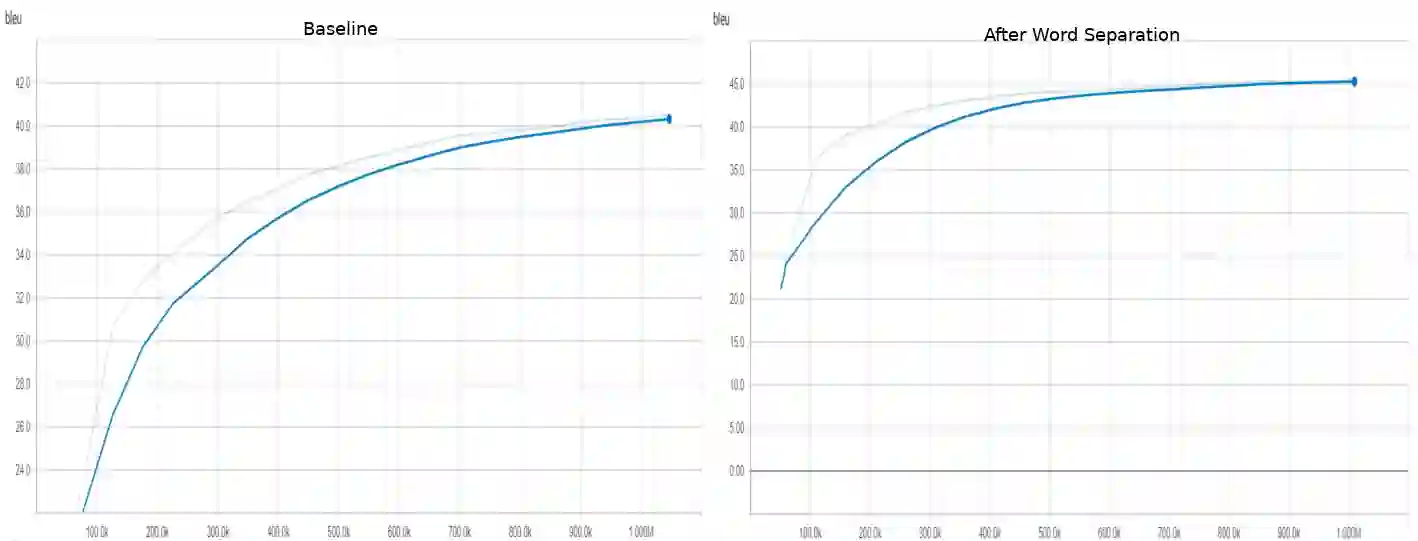
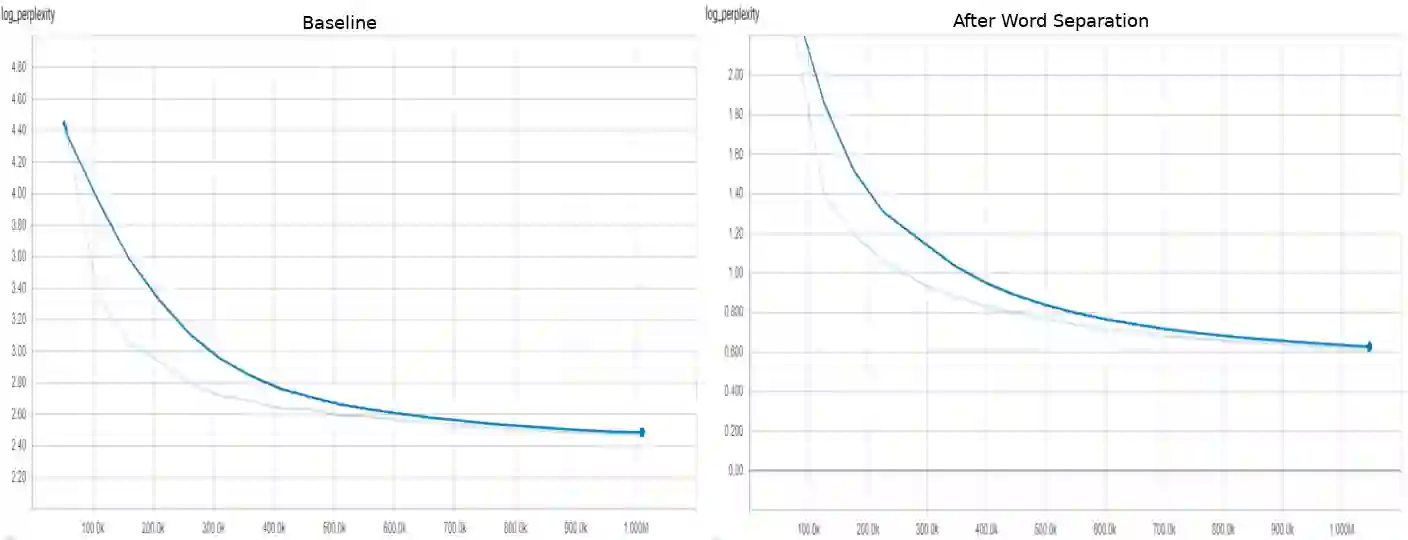
Indonesian is an agglutinative language since it has a compounding process of word-formation. Therefore, the translation model of this language requires a mechanism that is even lower than the word level, referred to as the sub-word level. This compounding process leads to a rare word problem since the number of vocabulary explodes. We propose a strategy to address the unique word problem of the neural machine translation (NMT) system, which uses Indonesian as a pair language. Our approach uses a rule-based method to transform a word into its roots and accompanied affixes to retain its meaning and context. Using a rule-based algorithm has more advantages: it does not require corpus data but only applies the standard Indonesian rules. Our experiments confirm that this method is practical. It reduces the number of vocabulary significantly up to 57\%, and on the English to Indonesian translation, this strategy provides an improvement of up to 5 BLEU points over a similar NMT system that does not use this technique.
翻译:印度尼西亚语是一种隐含语言,因为它具有一个复用字形的复合过程。 因此,该语言的翻译模式需要一个甚至比字级更低的机制, 被称为子字级。 这个复合过程导致自词汇数爆炸以来一个罕见的字问题。 我们提出了一个战略来解决神经机翻译系统独有的字问题, 该系统使用印度尼西亚语作为配对语言。 我们的方法是使用基于规则的方法将一个词变成其根, 并伴随一些细节来保留其含义和背景。 使用基于规则的算法具有更大的优势: 它不需要基本数据,而只是适用印度尼西亚的标准规则。 我们的实验证实这一方法是实用的。 它将词汇数量大大减少到57 ⁇, 在英语到印度尼西亚语的翻译上, 该战略比一个不使用这一技术的类似NMT系统改进了多达5个BLEU点。