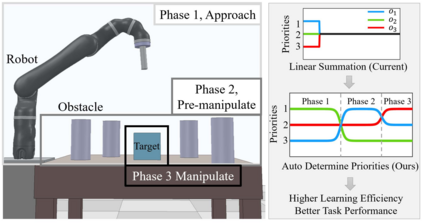
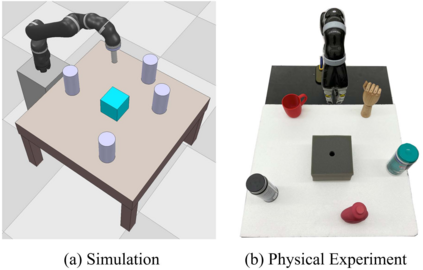
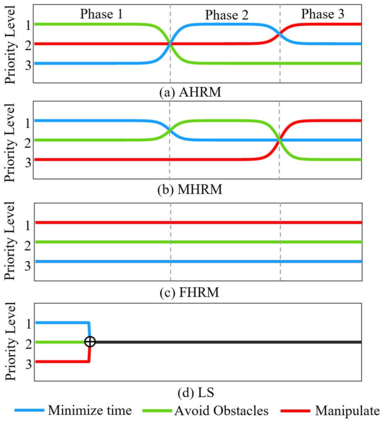
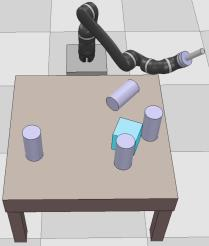
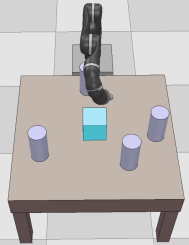
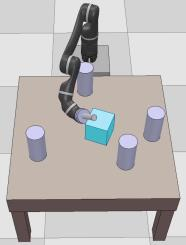
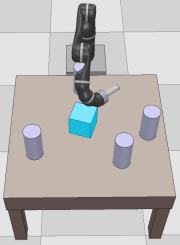
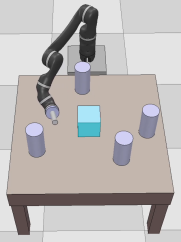
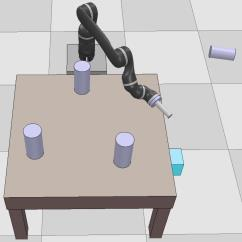
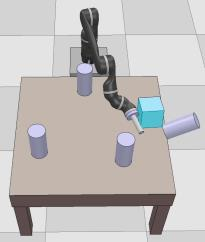
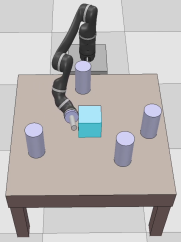
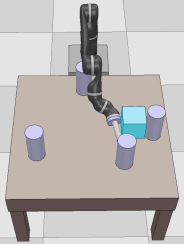
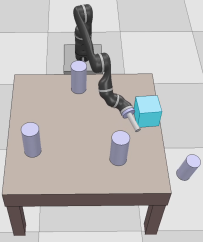
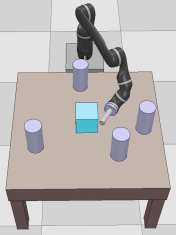
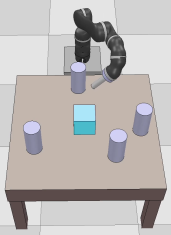
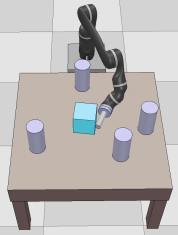
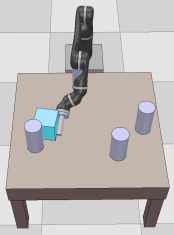
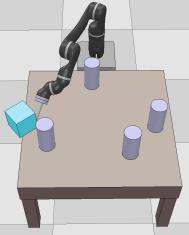
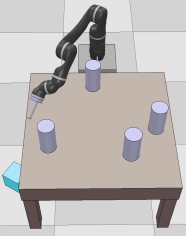
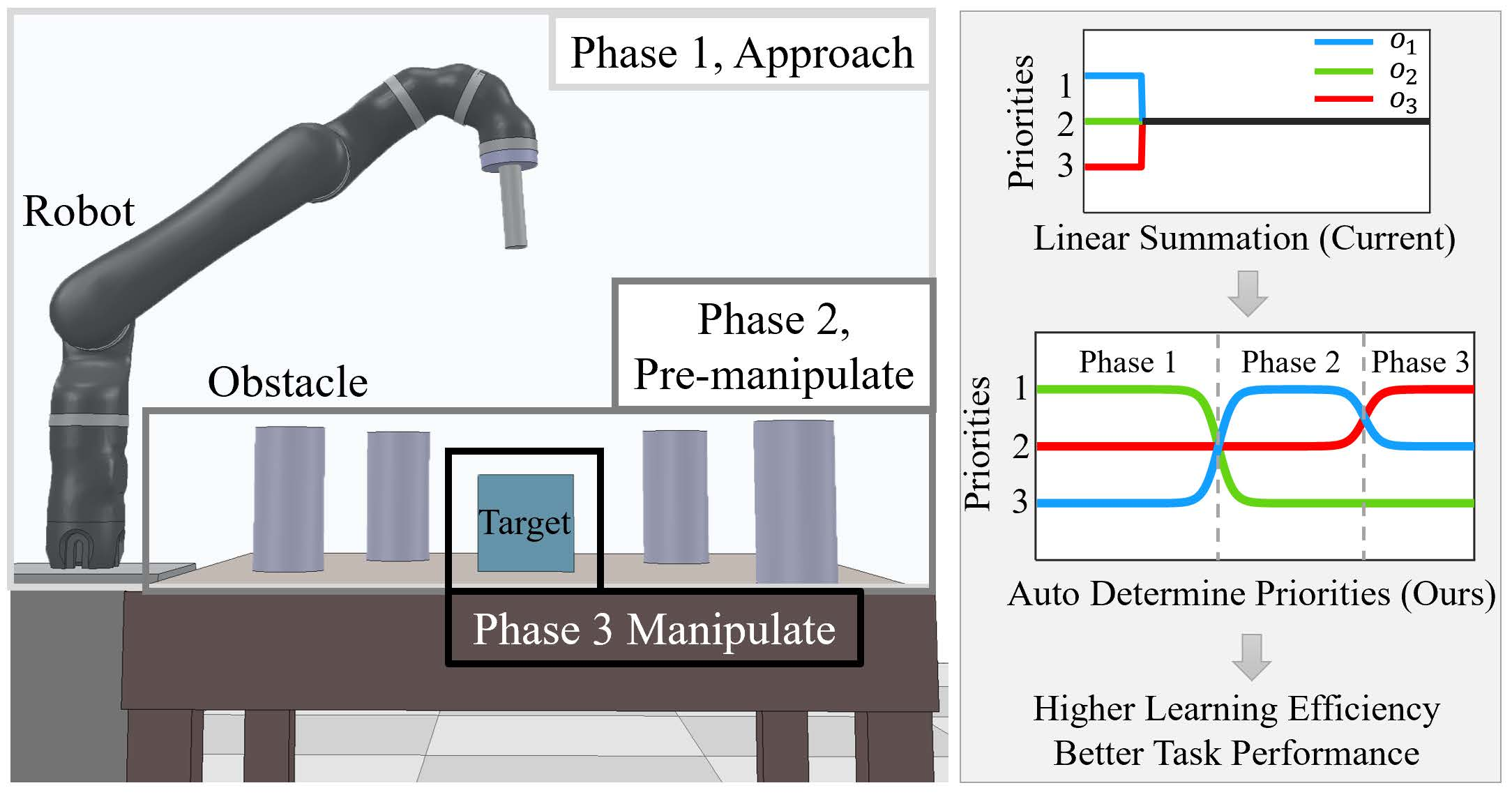
Dexterous manipulation tasks usually have multiple objectives, and the priorities of these objectives may vary at different phases of a manipulation task. Varying priority makes a robot hardly or even failed to learn an optimal policy with a deep reinforcement learning (DRL) method. To solve this problem, we develop a novel Adaptive Hierarchical Reward Mechanism (AHRM) to guide the DRL agent to learn manipulation tasks with multiple prioritized objectives. The AHRM can determine the objective priorities during the learning process and update the reward hierarchy to adapt to the changing objective priorities at different phases. The proposed method is validated in a multi-objective manipulation task with a JACO robot arm in which the robot needs to manipulate a target with obstacles surrounded. The simulation and physical experiment results show that the proposed method improved robot learning in task performance and learning efficiency.
翻译:不相干操纵任务通常具有多重目标,而且这些目标的优先事项在操纵任务的不同阶段可能各不相同。 不同的优先级使得机器人几乎或甚至无法学习一种最佳政策,采用深层强化学习(DRL)方法。 为了解决这个问题,我们开发了一个新型的适应性等级奖励机制(AHRM)来指导DRL代理机构学习具有多重优先目标的操纵任务。 AHRM可以确定学习过程中的客观优先事项,并更新奖励等级,以适应不同阶段不断变化的目标优先事项。 拟议的方法在多目标操作任务中被验证, 由JACO机器人臂操作, 机器人需要用环绕障碍来操纵目标。 模拟和物理实验结果显示, 拟议的方法可以改进机器人在任务性能和学习效率方面的学习。