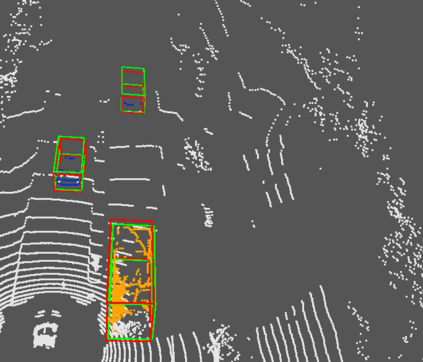
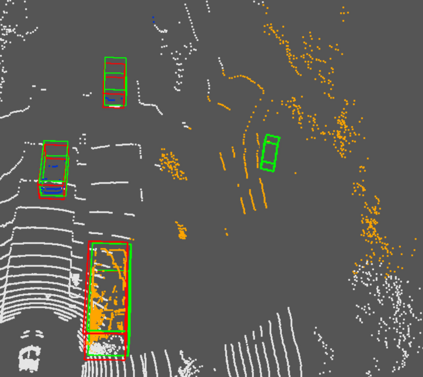
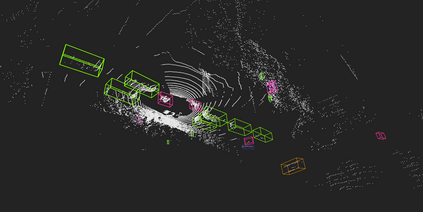
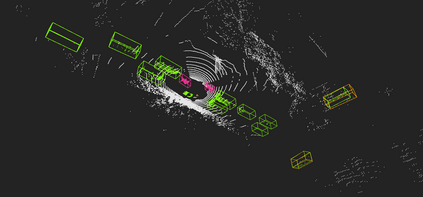
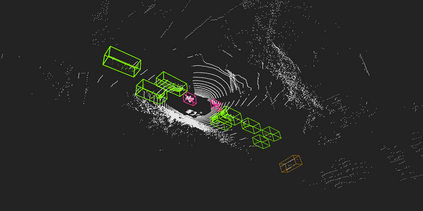
Accurate detection of obstacles in 3D is an essential task for autonomous driving and intelligent transportation. In this work, we propose a general multimodal fusion framework FusionPainting to fuse the 2D RGB image and 3D point clouds at a semantic level for boosting the 3D object detection task. Especially, the FusionPainting framework consists of three main modules: a multi-modal semantic segmentation module, an adaptive attention-based semantic fusion module, and a 3D object detector. First, semantic information is obtained for 2D images and 3D Lidar point clouds based on 2D and 3D segmentation approaches. Then the segmentation results from different sensors are adaptively fused based on the proposed attention-based semantic fusion module. Finally, the point clouds painted with the fused semantic label are sent to the 3D detector for obtaining the 3D objection results. The effectiveness of the proposed framework has been verified on the large-scale nuScenes detection benchmark by comparing it with three different baselines. The experimental results show that the fusion strategy can significantly improve the detection performance compared to the methods using only point clouds, and the methods using point clouds only painted with 2D segmentation information. Furthermore, the proposed approach outperforms other state-of-the-art methods on the nuScenes testing benchmark.
翻译:3D 中障碍的准确检测是自动驾驶和智能运输的一项基本任务。 在这项工作中,我们提议建立一个通用的多式联运融合框架 FisionPaint, 将 2D RGB 图像和 3D 点云在语义层面上结合, 以提升 3D 对象检测任务。 特别是, FusionPaint 框架由三个主要模块组成: 多模式语义分离模块、 适应性关注性语义融合模块和 3D 对象探测器。 首先, 以 2D 和 3D 分解方法为基础, 获得 2D 图像和 3D 利达尔 点云的语义化信息。 然后, 不同的传感器的分解结果根据拟议的基于关注的语义融合模块, 适应性地结合。 最后, 与 3D 连接的语义标志所绘制的点云, 以获得 3D 反对的结果。 提议的框架的有效性通过与其他三个不同的基准进行比较, 得到验证。 实验结果显示, 组合战略的分化结果能够大大改进2D 与状态测试方法。