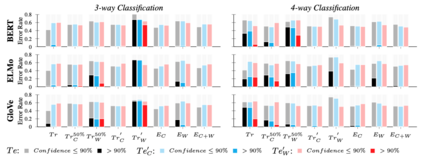
With the increasing use of machine-learning driven algorithmic judgements, it is critical to develop models that are robust to evolving or manipulated inputs. We propose an extensive analysis of model robustness against linguistic variation in the setting of deceptive news detection, an important task in the context of misinformation spread online. We consider two prediction tasks and compare three state-of-the-art embeddings to highlight consistent trends in model performance, high confidence misclassifications, and high impact failures. By measuring the effectiveness of adversarial defense strategies and evaluating model susceptibility to adversarial attacks using character- and word-perturbed text, we find that character or mixed ensemble models are the most effective defenses and that character perturbation-based attack tactics are more successful.
翻译:随着越来越多地使用机器学习驱动的算法判断,至关重要的是要开发能够适应不断演变或操纵的投入的模型。我们提议对设计欺骗性新闻探测过程中的语言差异进行广泛分析,这是在网上散布错误信息的情况下的一项重要任务。我们考虑两项预测任务,比较三个最先进的嵌入点,以突出模型性能、高度信任误判和高影响失灵方面的一致趋势。通过衡量对抗性防御战略的有效性,并使用字形和字形干扰文字来评估对对抗性攻击的易发性模型,我们发现性格或混合组合式模型是最有效的防御手段,特征扰动攻击战术更成功。