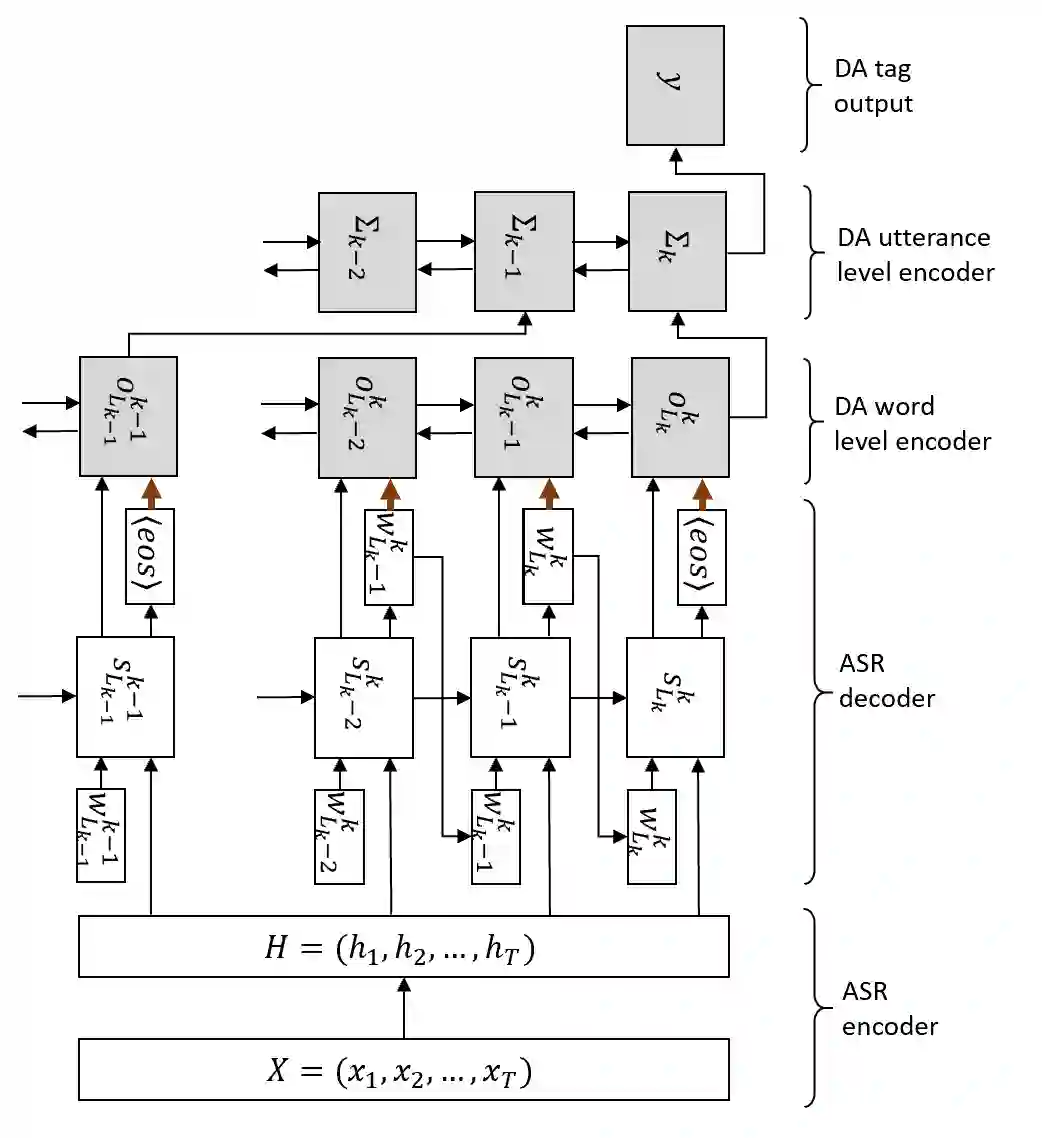
Spoken language understanding, which extracts intents and/or semantic concepts in utterances, is conventionally formulated as a post-processing of automatic speech recognition. It is usually trained with oracle transcripts, but needs to deal with errors by ASR. Moreover, there are acoustic features which are related with intents but not represented with the transcripts. In this paper, we present an end-to-end model which directly converts speech into dialog acts without the deterministic transcription process. In the proposed model, the dialog act recognition network is conjunct with an acoustic-to-word ASR model at its latent layer before the softmax layer, which provides a distributed representation of word-level ASR decoding information. Then, the entire network is fine-tuned in an end-to-end manner. This allows for stable training as well as robustness against ASR errors. The model is further extended to conduct DA segmentation jointly. Evaluations with the Switchboard corpus demonstrate that the proposed method significantly improves dialog act recognition accuracy from the conventional pipeline framework.
翻译:口头语言理解,在语音中提取意向和(或)语义概念,通常作为自动语音识别处理后的一种后处理方式,形成对话行为识别网络,通常使用手语记录誊本,但需要由ASR处理错误。此外,还有声学特征与意图相关,但与记录誊本无关。在本文中,我们提出了一个端对端模式,直接将语音转换成对话行为,而没有确定性笔录过程。在拟议模式中,对话行为识别网络与软式层前的潜层的ASR 声对字模型相连接,后者提供分布式的ASR解码信息。然后,整个网络以端对端方式进行微调,这样既能进行稳定的培训,又能防止ASR错误的稳健性。该模式还进一步扩展为联合进行DA分解。与总机体的评估表明,拟议方法大大改进了对话在常规管道框架中的识别精确度。