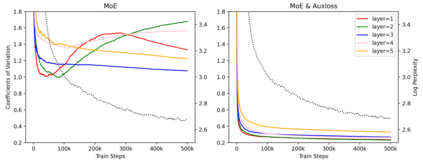
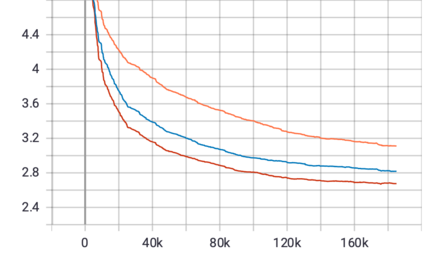
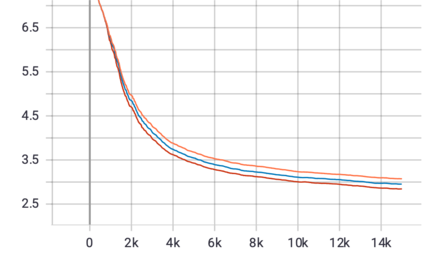
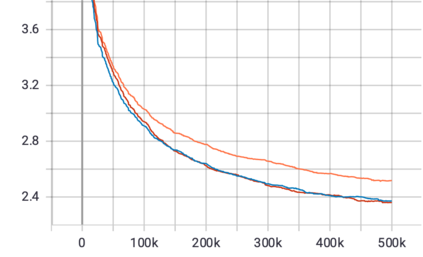
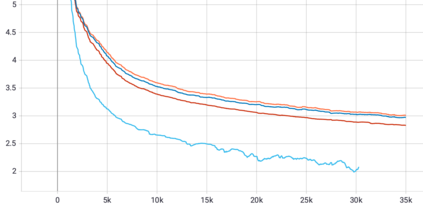
Mixture-of-Experts (MoE) models can achieve promising results with outrageous large amount of parameters but constant computation cost, and thus it has become a trend in model scaling. Still it is a mystery how MoE layers bring quality gains by leveraging the parameters with sparse activation. In this work, we investigate several key factors in sparse expert models. We observe that load imbalance may not be a significant problem affecting model quality, contrary to the perspectives of recent studies, while the number of sparsely activated experts $k$ and expert capacity $C$ in top-$k$ routing can significantly make a difference in this context. Furthermore, we take a step forward to propose a simple method called expert prototyping that splits experts into different prototypes and applies $k$ top-$1$ routing. This strategy improves the model quality but maintains constant computational costs, and our further exploration on extremely large-scale models reflects that it is more effective in training larger models. We push the model scale to over $1$ trillion parameters and implement it on solely $480$ NVIDIA V100-32GB GPUs, in comparison with the recent SOTAs on $2048$ TPU cores. The proposed giant model achieves substantial speedup in convergence over the same-size baseline.
翻译:在这项工作中,我们调查了稀少专家模型中的若干关键因素。我们发现,与最近研究的观点相反,负载不平衡可能不是一个影响模型质量的重大问题,而低效专家人数和专家能力(最高至1千元),最高至1千元的定线数可以大大改变这种情况。此外,我们向前迈出了一步,提出了一种简单的方法,称为专家原型,将专家分成不同的原型,并应用最高至1百万美元的定线。这一战略改进了模型质量,但保持了不断的计算成本,我们对极大型模型的进一步探索表明,它在培训大型模型方面更为有效。我们把模型规模推到超过1万亿元的参数上,并在仅480美元NDIA V100-32的定线参数上实施。我们比较了一种叫作专家原型的专家原型方法,将专家分成不同的原型,采用最高至1百万美元的定线。这个战略改进了模型的质量,但保持了不变的计算成本,我们对极大型模型的进一步探索表明,它在培训大型模型方面更为有效。我们把模型推向1万亿美元以上的参数,并在仅480美元V100-32GPPU中执行它,以近20个核心基准速度达到20美元。