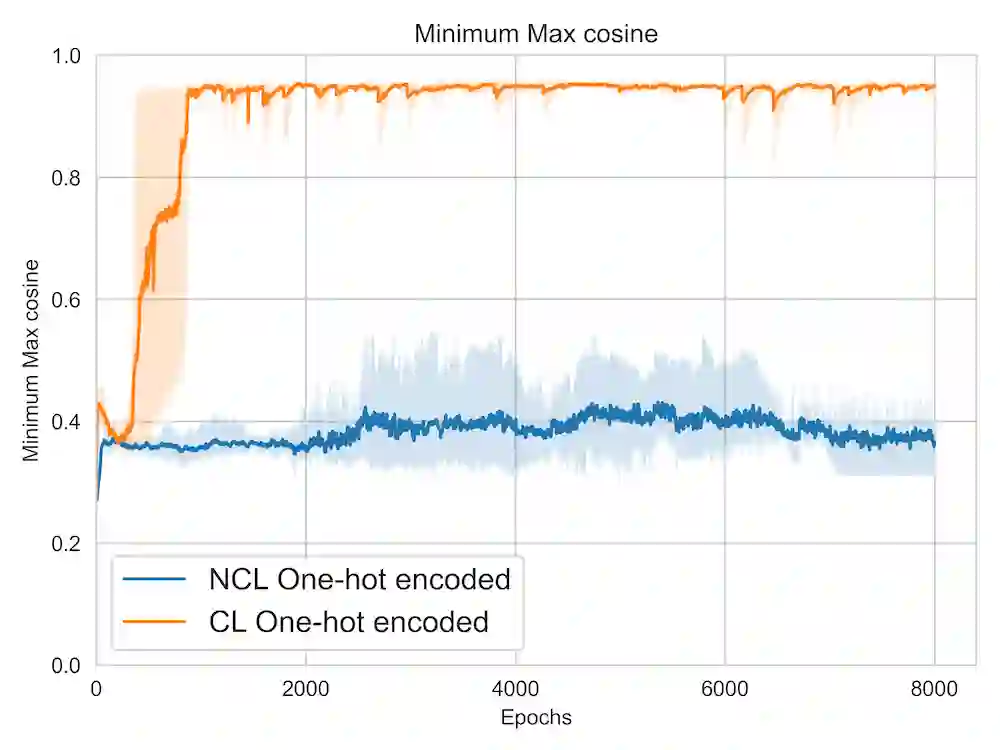
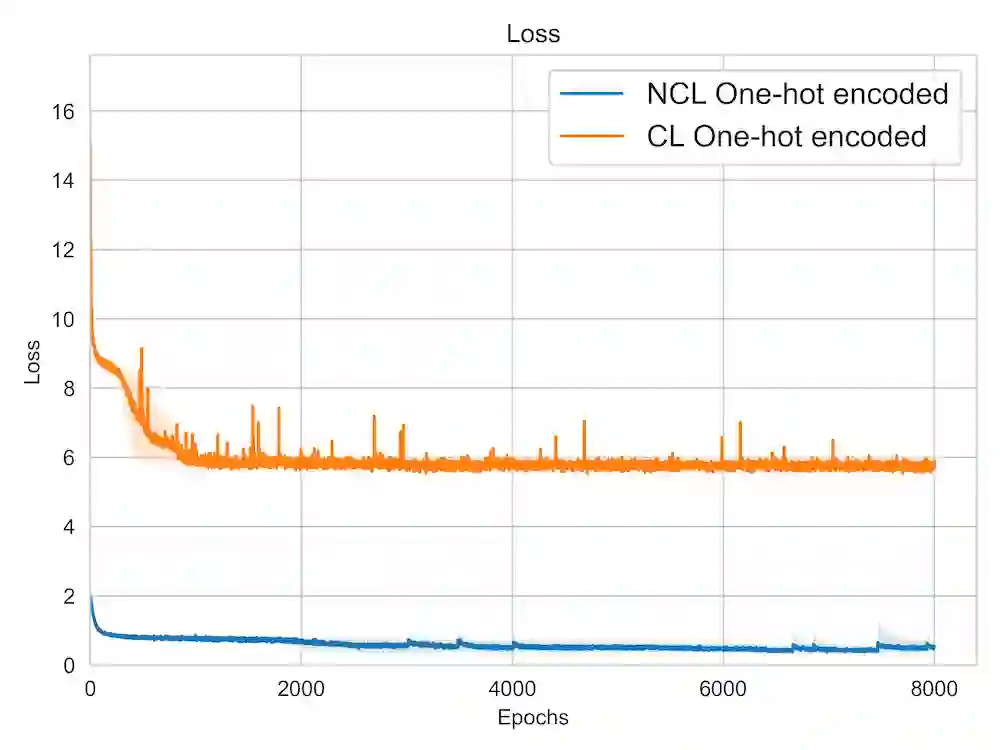
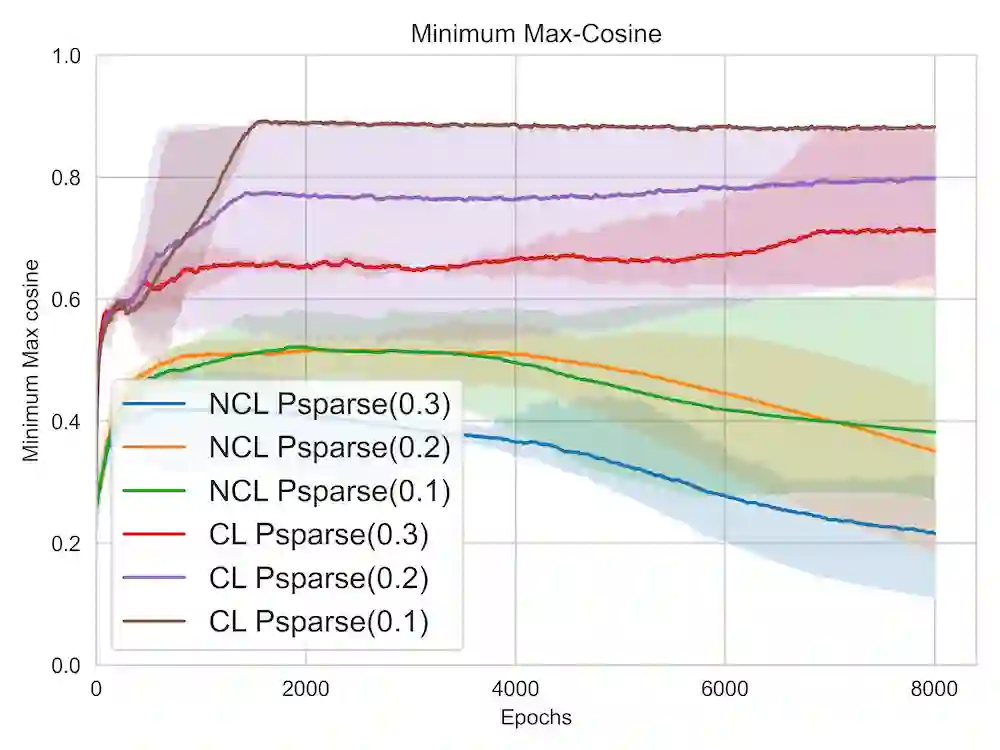
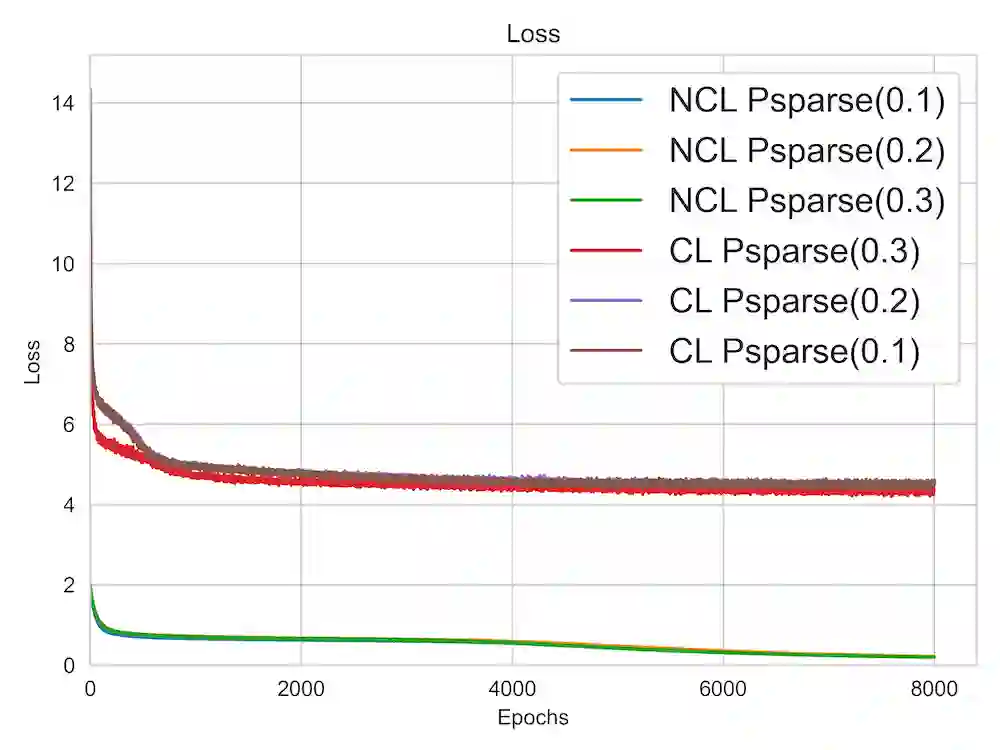
A lot of recent advances in unsupervised feature learning are based on designing features which are invariant under semantic data augmentations. A common way to do this is contrastive learning, which uses positive and negative samples. Some recent works however have shown promising results for non-contrastive learning, which does not require negative samples. However, the non-contrastive losses have obvious "collapsed" minima, in which the encoders output a constant feature embedding, independent of the input. A folk conjecture is that so long as these collapsed solutions are avoided, the produced feature representations should be good. In our paper, we cast doubt on this story: we show through theoretical results and controlled experiments that even on simple data models, non-contrastive losses have a preponderance of non-collapsed bad minima. Moreover, we show that the training process does not avoid these minima.
翻译:在未经监督的特征学习方面最近取得的许多进展都基于设计特征,这些特征在语义数据增强下是变化无常的。一种常见的方法是对比性学习,它使用正和负的样本。然而,最近的一些作品显示,非争议性学习有希望的结果,而不需要负的样本。然而,非争议性损失有明显的“折叠”迷你,其中编码器在不依赖输入的情况下产生一个持续嵌入的特征。民间猜测是,只要避免这些崩溃的解决方案,产生的特征表现应该是好的。在我们的论文中,我们对这个故事表示怀疑:我们通过理论结果和有控制的实验显示,即使是在简单的数据模型上,非争议性损失也大多是非崩溃的坏迷你。此外,我们表明,培训过程不会避免这些微型现象。