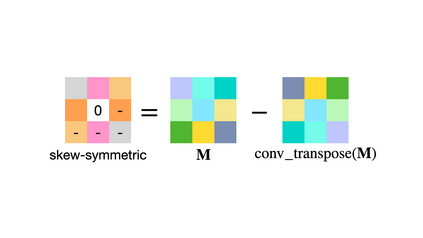
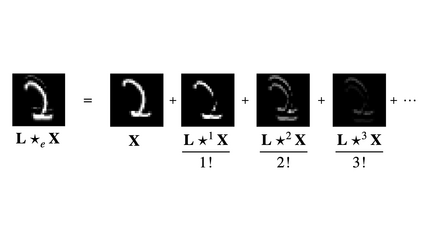
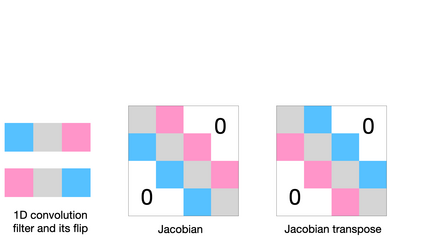
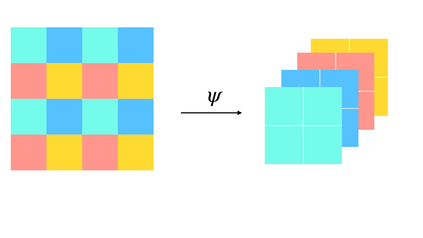
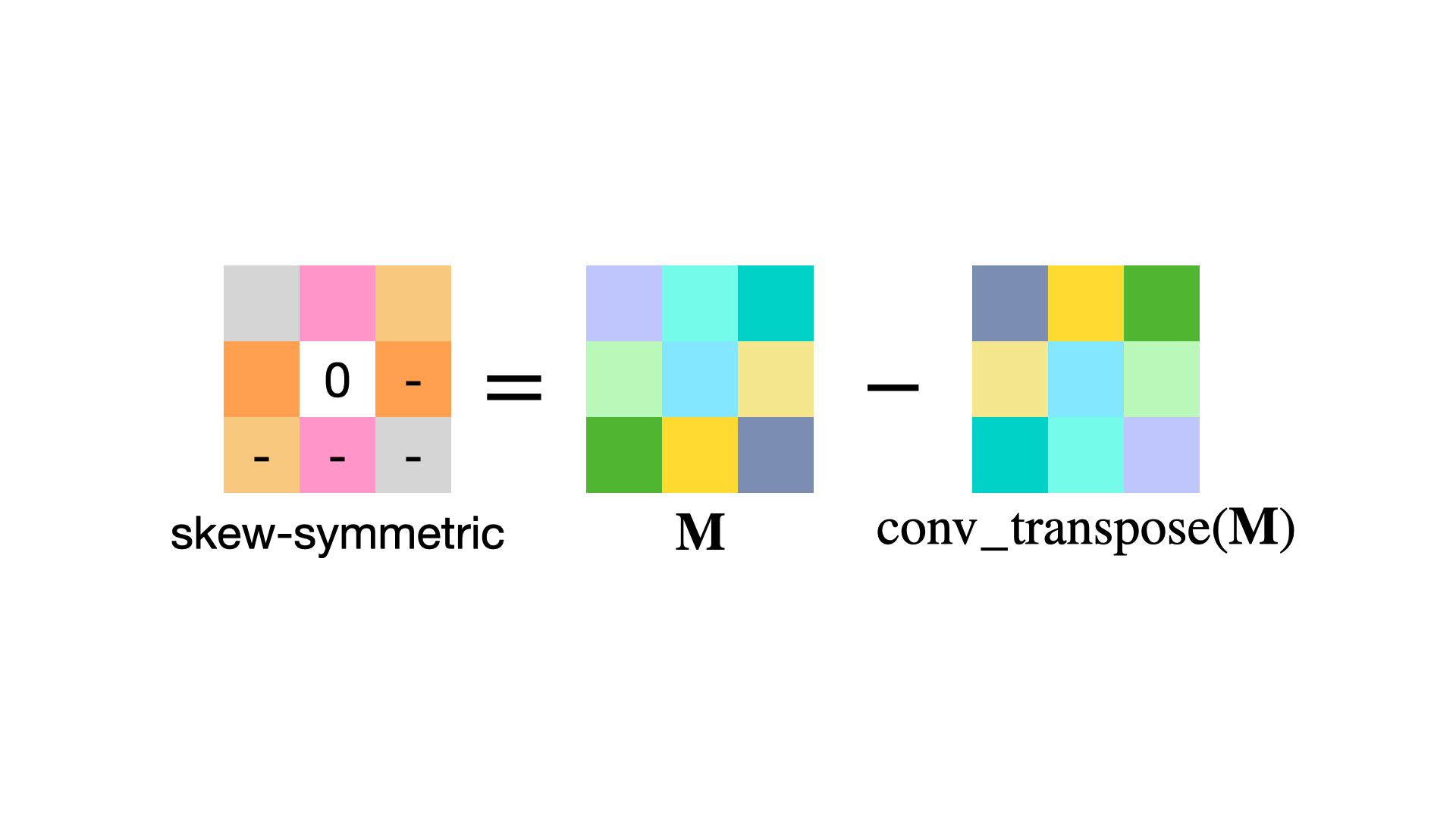
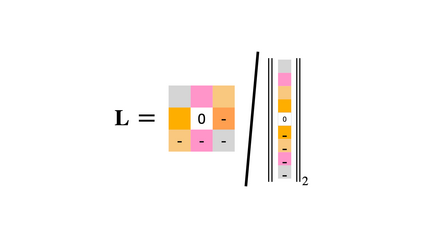Training convolutional neural networks with a Lipschitz constraint under the $l_{2}$ norm is useful for provable adversarial robustness, interpretable gradients, stable training, etc. While 1-Lipschitz networks can be designed by imposing a 1-Lipschitz constraint on each layer, training such networks requires each layer to be gradient norm preserving (GNP) to prevent gradients from vanishing. However, existing GNP convolutions suffer from slow training, lead to significant reduction in accuracy and provide no guarantees on their approximations. In this work, we propose a GNP convolution layer called \methodnamebold\ (\methodabv) that uses the following mathematical property: when a matrix is {\it Skew-Symmetric}, its exponential function is an {\it orthogonal} matrix. To use this property, we first construct a convolution filter whose Jacobian is Skew-Symmetric. Then, we use the Taylor series expansion of the Jacobian exponential to construct the \methodabv\ layer that is orthogonal. To efficiently implement \methodabv, we keep a finite number of terms from the Taylor series and provide a provable guarantee on the approximation error. Our experiments on CIFAR-10 and CIFAR-100 show that \methodabv\ allows us to train provably Lipschitz, large convolutional neural networks significantly faster than prior works while achieving significant improvements for both standard and certified robust accuracies.
翻译:以利普西特标准为标准, 以利普西特标准为标准, 防止梯度消失。 然而, 现有的国产总值标准在培训过程中受到缓慢的制约, 导致精确度大幅下降, 并且无法保证其近似值。 在这项工作中, 我们提议一个名为\methodnamebold\\ (methodabiv)的国产总值平衡层, 使用以下数学属性: 当一个矩阵是 skew- Symlogy 时, 它的指数功能是 rit 或thopotictrt 矩阵。 为了使用这一属性, 我们首先建立一个叶戈比斯对称的递增过滤器。 然后, 我们用叶戈比斯指数的系列扩展来构建一个名为\methothodnamebold\ (methodadamav) 层, 它使用以下数学属性: 当一个矩阵是 Shew- Systew- Sylorvral 网络时, 它的指数可以大幅快速运行, 和 IM IMRILILIal 测试, 。 提供一个更快速的硬化的硬化的模型, 。