CVPR 2018 | 美国东北大学提出MoNet,使用紧密池化缓解特征高维问题
选自arXiv
作者:Mengran Gou等
机器之心编译
参与:路雪、黄小天、邱陆陆
近日,来自美国东北大学和美国信息科学研究所的研究者联合发布论文《MoNet: Moments Embedding Network》,提出 MoNet 网络,使用新型子矩阵平方根层,在双线性池化之前执行矩阵归一化,结合紧凑池化在不损害性能的前提下大幅降低维度,其性能优于 G^2DeNet。目前该论文已被 CVPR 2018 接收。
将图像的局部表示嵌入成既具有代表性、又不受轻微噪声影响的特征,是很多计算机视觉任务中的重要一步。在深度卷积神经网络(CNN)成功之前,研究人员使用手动的连续独立步骤解决该问题。典型包括 HOG、SIFT、协方差描述子、VLAD、Fisher 向量和双线性池化。尽管 CNN 是端到端地训练的,但是它们可以被看作两部分:卷积层负责特征提取步骤,后面的全连接层是编码步骤。现在已有多项研究探索用卷积嵌入方法替换全连接层,无论训练采用两段式还是端到端方式。

表 1. 不同神经网络的二阶统计信息对比。双线性 CNN(BCNN)仅具备二阶信息,没有使用矩阵归一化。改进后的 BCNN(iBCNN)和 G^2DeNet 都利用了矩阵归一化,但是都受制于高维度,因为它们需要计算一个很大的池化矩阵的平方根。本论文提出的 MoNet,在新型子矩阵平方根层(sub-matrix square-root layer)的帮助下,可以直接归一化局部特征,同时,通过使用紧凑池化(compact pooling)替代全双线性池化,可以大幅降低最后的表示维度。
双线性 CNN 由 Lin et al. 首次提出,旨在池化不同空间位置的二阶统计信息。双线性池化已被证明在多项任务中有用,包括细粒度图像分类、大规模图像识别、分割、视觉问答、人脸识别和艺术风格重建。Wang et al. 提出,使用高斯嵌入层纳入一阶信息。实践证明,归一化方法对这些 CNN 的性能也很重要。研究者提出了两种归一化方法用于双线性池化矩阵:对于
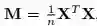
其中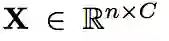
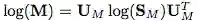
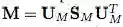
另一方面,Wang et al. 提出矩阵方幂(matrix-power)方法,将 M 非线性地扩展到
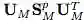
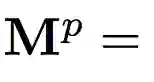
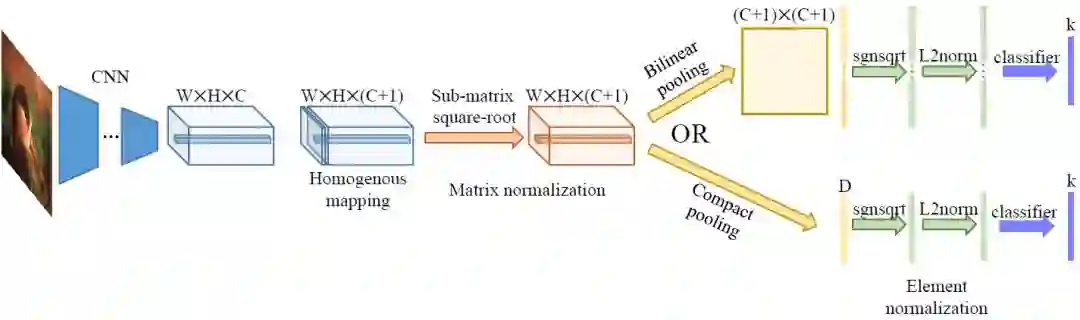
图 1. 论文提出的 MoNet 架构图示。该架构使用论文提出的子矩阵平方根层,这使得在双线性池化之前执行矩阵归一化或进一步使用紧凑池化,在不损害性能的前提下大幅降低维度成为可能。
上述特征编码的一个重要缺陷是编码后特征的维度极高。由于张量相乘,最后的特征维度是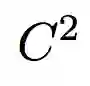
本论文使用同质填充局部特征(homogeneous padded local feature)的张量积重写了 G^2DeNet 的方程,使之对齐 BCNN 架构,以使高斯嵌入操作和双线性池化解耦合。本论文没有特别关注双线性池化矩阵 M,而是推导出子矩阵平方根层,对(非)同质局部特征上直接执行矩阵方幂归一化。在新型子矩阵平方根层的帮助下,研究者利用紧凑池化逼近张量积,同时使维度更低。
本论文的贡献有以下三方面:
利用实证矩矩阵(moment matrix)结合 G^2DeNet 和双线性池化 CNN,并将高斯嵌入与双线性池化解耦合。
提出新型子矩阵平方根层,在双线性池化层之前直接对特征执行归一化处理,从而利用紧凑池化降低表示的维度。
利用矩阵反向传播推导出子矩阵平方根层的梯度,这样 MoNet 架构可以进行协同优化。
MoNet
MoNet 网络的架构概述如上述图 1 所示。在本节中,我们将详述每个模块的设计。
对于输入图像 I,ReLU X 之后最后一个卷积层的输出由整个空间位置 i = 1, 2, . . . , n 上的局部特征 x_i 组成。接着,我们将其映射到齐次坐标,方法是添加额外的值为 1 的维度,并把所有元素除以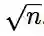
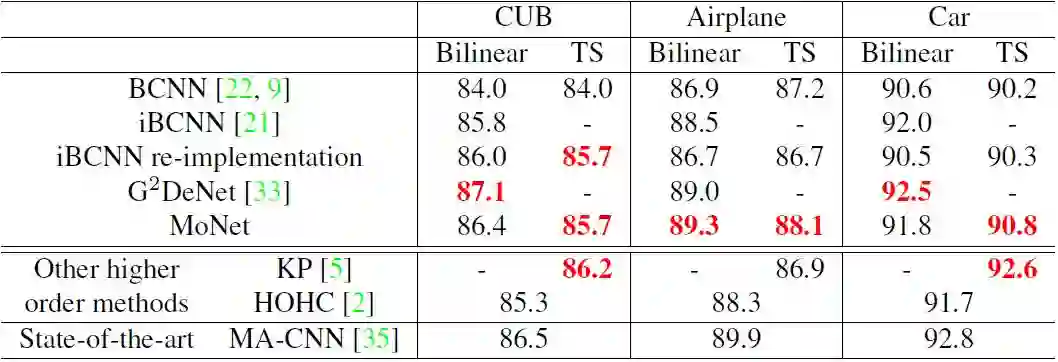
表 4:细粒度分类上的实验结果。双线性和 TS 分别表征全双线性池化和 Tensor Sketch 紧密池化。每栏中的最佳表现标为红色。
论文:MoNet: Moments Embedding Network

论文链接:https://arxiv.org/abs/1802.07303
近期双线性池化作为一种特征编码层被提出,可在深度网络的卷积层之后使用,提升在多个视觉任务中的表现。与传统的全局平均池化层或全连接层相比,双线性池化以平移不变式的形式收集二阶信息。但是,这一池化层家族的一个严重弊端是其维度爆炸。为解决这一问题,已探索了紧密的近似池化方法。另外,最近成果表明,通过矩阵归一化来调整不稳定的较高阶信息可获得显著的性能提升。然而,紧密池化与矩阵归一化的结合至今未被探索。
在本论文中,我们通过实证矩矩阵结合了双线性池化层与全局高斯嵌入层。此外,我们提出一个全新的子矩阵平方根层,借助此层,可以直接归一化卷积层的输出,并通过现成的紧密池化方法来缓解维度问题。我们在三个广泛使用的细粒度分类数据集上进行了实验,实验表明,我们提出的 MoNet 架构相比 G^2DeNet 架构有着更好的表现。与紧密池化技术结合使用时,本方法可以用维度数降低了 96% 的编码特征获得可比的表现。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



