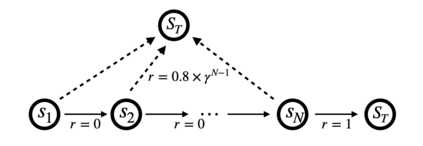
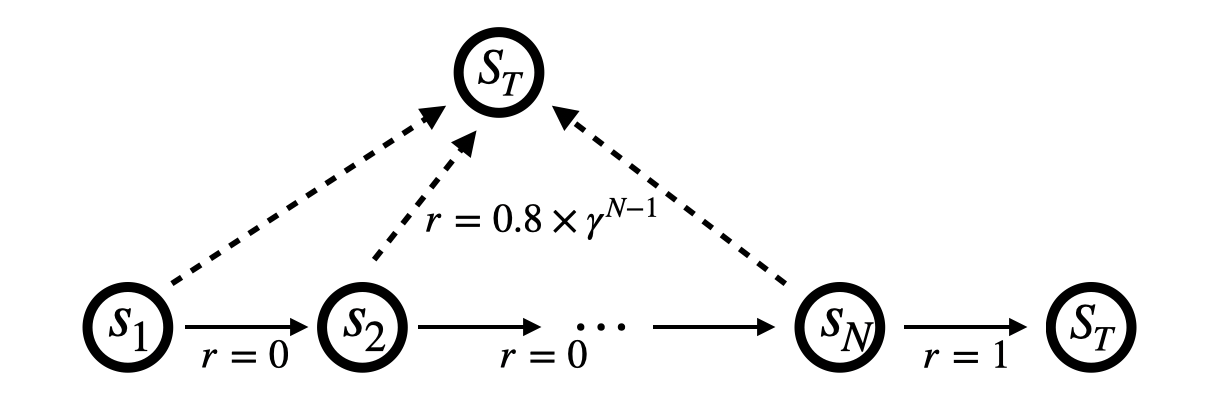
In this paper, we establish the global optimality and convergence rate of an off-policy actor critic algorithm in the tabular setting without using density ratio to correct the discrepancy between the state distribution of the behavior policy and that of the target policy. Our work goes beyond existing works on the optimality of policy gradient methods in that existing works use the exact policy gradient for updating the policy parameters while we use an approximate and stochastic update step. Our update step is not a gradient update because we do not use a density ratio to correct the state distribution, which aligns well with what practitioners do. Our update is approximate because we use a learned critic instead of the true value function. Our update is stochastic because at each step the update is done for only the current state action pair. Moreover, we remove several restrictive assumptions from existing works in our analysis. Central to our work is the finite sample analysis of a generic stochastic approximation algorithm with time-inhomogeneous update operators on time-inhomogeneous Markov chains, based on its uniform contraction properties.
翻译:在本文中,我们在表格设置中,在没有使用密度比率来纠正行为政策与目标政策之间国家分布差异的情况下,确定一个非政策性行为者批评算法的全球最佳性和趋同率。我们的工作超越了政策梯度方法最佳性的现有工作,因为现有工作使用精确的政策梯度来更新政策参数,而我们则使用一个近似和随机更新步骤。我们更新的步骤不是一个梯度更新,因为我们没有使用密度比率来纠正国家分布,这与从业者所做的完全吻合。我们更新是近似,因为我们使用了一个学习的批评家,而不是真正的价值函数。我们更新是随机的,因为每一步更新都是针对当前对州行动的。此外,我们删除了我们分析中现有工作中的若干限制性假设。我们工作的核心是对具有时间-不相容性马尔科夫链操作者基于其统一的收缩特性的具有时间-不相容性的最新操作者进行有限的抽样分析。