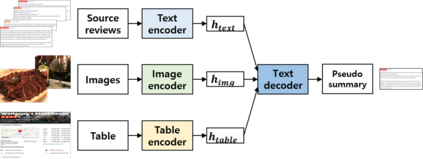
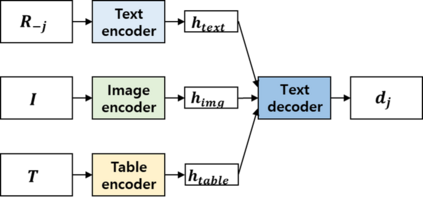
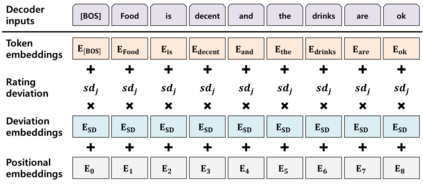
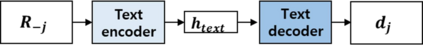Recently, opinion summarization, which is the generation of a summary from multiple reviews, has been conducted in a self-supervised manner by considering a sampled review as a pseudo summary. However, non-text data such as image and metadata related to reviews have been considered less often. To use the abundant information contained in non-text data, we propose a self-supervised multimodal opinion summarization framework called MultimodalSum. Our framework obtains a representation of each modality using a separate encoder for each modality, and the text decoder generates a summary. To resolve the inherent heterogeneity of multimodal data, we propose a multimodal training pipeline. We first pretrain the text encoder--decoder based solely on text modality data. Subsequently, we pretrain the non-text modality encoders by considering the pretrained text decoder as a pivot for the homogeneous representation of multimodal data. Finally, to fuse multimodal representations, we train the entire framework in an end-to-end manner. We demonstrate the superiority of MultimodalSum by conducting experiments on Yelp and Amazon datasets.
翻译:最近,通过多种审查生成了摘要,通过将抽样审查视为假摘要,以自我监督的方式进行了意见总结,但与审查有关的图像和元数据等非文本数据却很少被考虑。为了使用非文本数据所载的大量信息,我们建议采用一个自监督的多式联运意见总结框架,称为多式Sum。我们的框架获得每种模式的表述,每个模式使用一个单独的编码器,文本解码器生成一个摘要。为了解决多式联运数据固有的异质性,我们建议建立一个多式联运培训管道。我们首先将纯基于文本模式数据的文本编码-解码器输入文本。随后,我们先将经过事先训练的文本解码器作为统一多式联运数据表述的要点,以此预设非文本模式编码器。最后,为了融合多式联运表述,我们以端到端的方式培训整个框架。我们通过对Yelp和亚马孙数据设置进行实验,展示了多式系统结构的优越性。