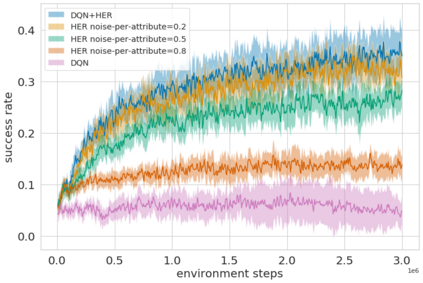
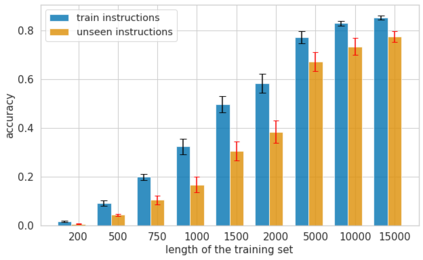
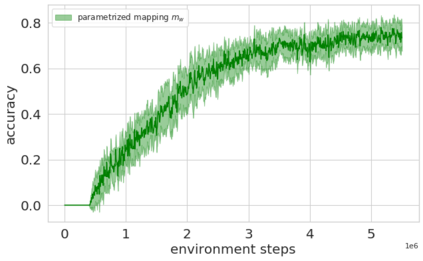
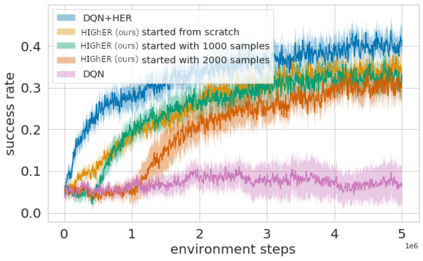
Language creates a compact representation of the world and allows the description of unlimited situations and objectives through compositionality. While these characterizations may foster instructing, conditioning or structuring interactive agent behavior, it remains an open-problem to correctly relate language understanding and reinforcement learning in even simple instruction following scenarios. This joint learning problem is alleviated through expert demonstrations, auxiliary losses, or neural inductive biases. In this paper, we propose an orthogonal approach called Hindsight Generation for Experience Replay (HIGhER) that extends the Hindsight Experience Replay (HER) approach to the language-conditioned policy setting. Whenever the agent does not fulfill its instruction, HIGhER learns to output a new directive that matches the agent trajectory, and it relabels the episode with a positive reward. To do so, HIGhER learns to map a state into an instruction by using past successful trajectories, which removes the need to have external expert interventions to relabel episodes as in vanilla HER. We show the efficiency of our approach in the BabyAI environment, and demonstrate how it complements other instruction following methods.
翻译:语言创造了一种对世界的缩略语,并允许通过构成性来描述无限的情况和目标。 虽然这些特征特征可以促进指导、调节或结构互动代理行为,但对于在情景之后的简单指令中正确描述语言理解和强化学习仍然是一个开放的问题。 这种共同学习问题通过专家演示、辅助损失或神经感应偏差来缓解。 在本文中,我们提议一种统称方法,称为Hindsight General for experience replay (HIGher), 将Hindsight Experience Replay (HER) 方法扩展到语言限制的政策设置。 当该代理不履行指令时, HIGher 学会发布与代理轨迹匹配的新指令, 并用正面的奖励重新标出事件。 为此, HIGher 学会使用过去成功的轨迹将状态映射成教学图, 从而不再需要外部专家干预, 来重新标出Vanilla HER 。 我们展示了我们在BeIAI环境中采用的方法的效率, 并展示它如何补充其他教学方法。