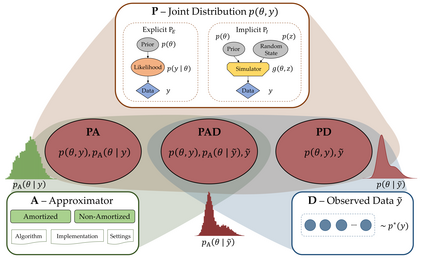
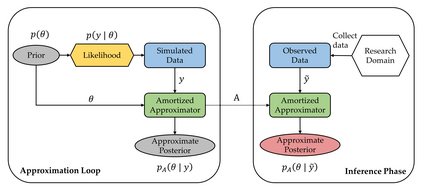
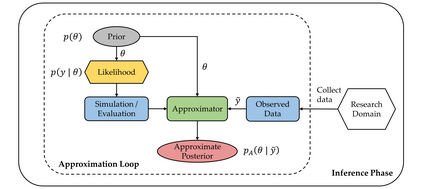
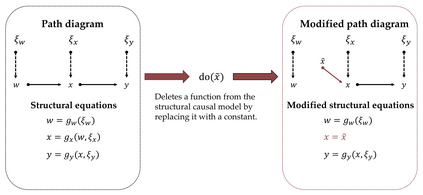
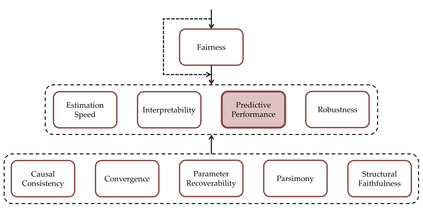
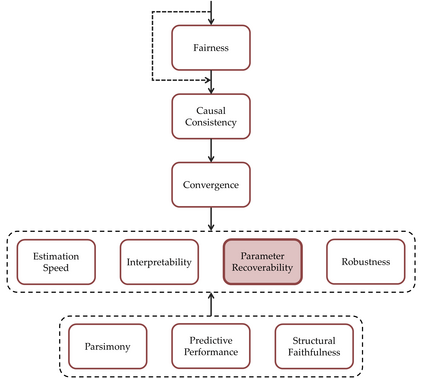
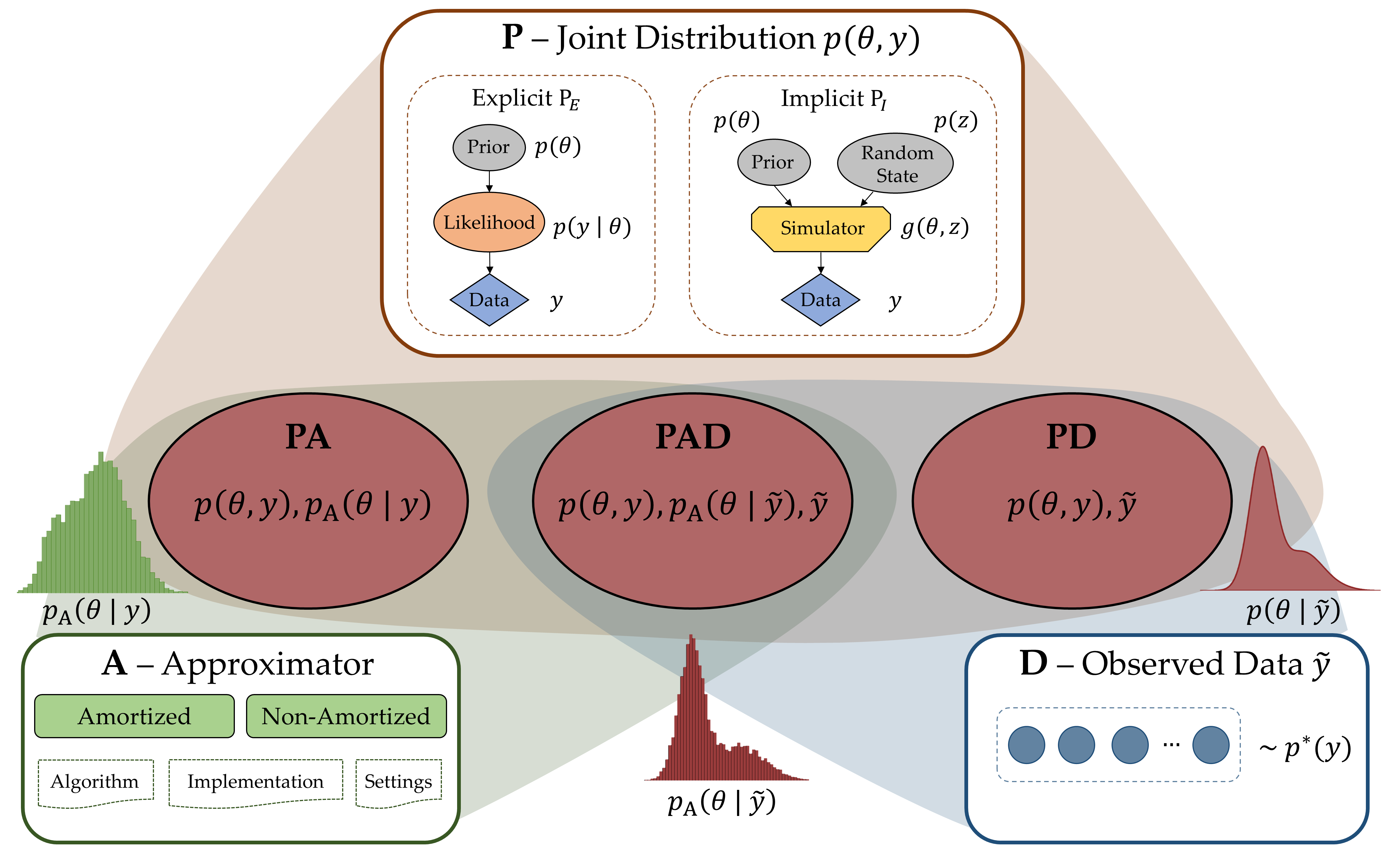
Probabilistic (Bayesian) modeling has experienced a surge of applications in almost all quantitative sciences and industrial areas. This development is driven by a combination of several factors, including better probabilistic estimation algorithms, flexible software, increased computing power, and a growing awareness of the benefits of probabilistic learning. However, a principled Bayesian model building workflow is far from complete and many challenges remain. To aid future research and applications of a principled Bayesian workflow, we ask and provide answers for what we perceive as two fundamental questions of Bayesian modeling, namely (a) "What actually is a Bayesian model?" and (b) "What makes a good Bayesian model?". As an answer to the first question, we propose the PAD model taxonomy that defines four basic kinds of Bayesian models, each representing some combination of the assumed joint distribution of all (known or unknown) variables (P), a posterior approximator (A), and training data (D). As an answer to the second question, we propose ten utility dimensions according to which we can evaluate Bayesian models holistically, namely, (1) causal consistency, (2) parameter recoverability, (3) predictive performance, (4) fairness, (5) structural faithfulness, (6) parsimony, (7) interpretability, (8) convergence, (9) estimation speed, and (10) robustness. Further, we propose two example utility decision trees that describe hierarchies and trade-offs between utilities depending on the inferential goals that drive model building and testing.
翻译:几乎在所有的定量科学和工业领域都出现了概率模型(Bayesian)的急剧增长。这一发展是由若干因素的结合推动的,其中包括更好的概率估算算法、灵活的软件、更高的计算能力,以及日益认识到概率学习的好处。然而,有原则的巴伊西亚模型建设工作流程远非完全,许多挑战依然存在。为了帮助今后研究和应用有原则的巴伊西亚工作流程,我们为巴伊西亚模型的两个基本问题(a) “贝伊西亚模型实际上是什么?” 和(b) “贝伊西亚模型是什么使好贝伊西亚模型是什么?” 。作为第一个问题的答案,我们提议PAD模型模型分类法定义了巴伊西亚模型的四种基本类型,每一种都代表了假定所有(已知或未知的)变量(P)、后方辅助工具(A)以及培训数据(D)的组合。作为第二个问题的答案,我们提议了十个效用层面,我们可以据此评估贝伊建模型的准确性模型, (7) 整体性测试, 结构性指标 (6) 恢复性指标 和结构性 (8) 。