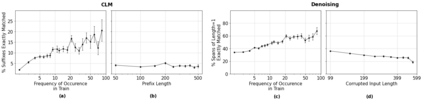
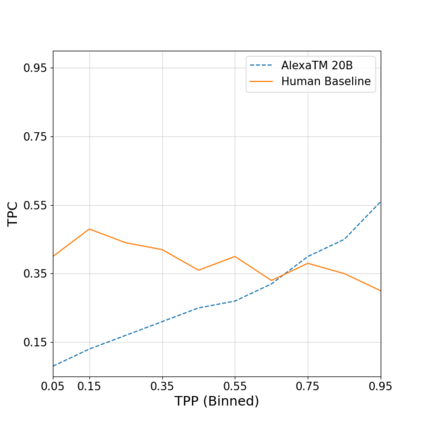
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
翻译:在这项工作中,我们证明,在拆卸和Causal语言建模(CLM)混合任务上经过预先培训的多语言大型序列到序列(seq2seq)模型比在各种任务上只拆解的模型(CLM)任务中只拆解的模型(CLM),更有效率的少见的学习者,尤其是,我们在Flores-101数据集(Alexa教师模型)(AlexaTM 20B)上培训了200亿个参数的多语言连锁模型(AlexaTM 20B),在一闪式拼凑任务中,比540B PaLM 脱coder模型(175B)要高得多。 AlexaTM 20B还实现了SOTA的一发机器翻译,特别是低资源语言翻译,几乎是该模型所支持的所有语文配对(阿拉伯文、英文、法文、德国文、印地文、意大利文、日文、马拉蒂、葡萄牙文、泰米尔和特卢古鲁古)中,我们还在零发模型中展示了SUGPTTE(175B)GPLULULULULU和SAVV2级的高级数据,作为XA-TA-TA-DSLS-S-DS-LS-DS-Axxxxxxx的模拟案例,在X的大规模业绩和S-S-S-LV-S-S-S-S-S-S-S-LV-S-S-S-S-A-A-Axxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx的模拟的模拟的模拟的模拟结果的模拟,以的模拟的模拟工作结果中展示的模拟,以的模拟中展示的模拟,还展示和S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-S-