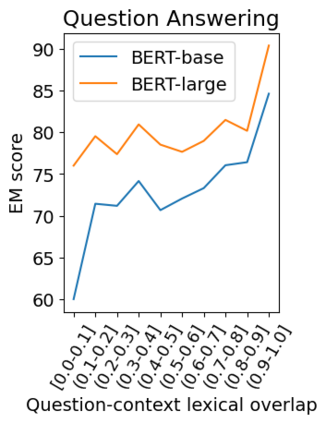
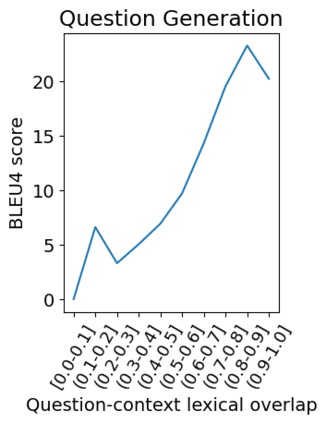
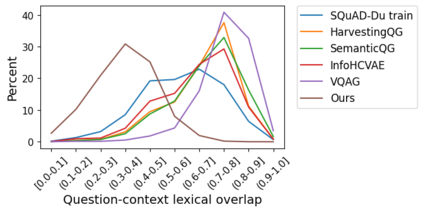
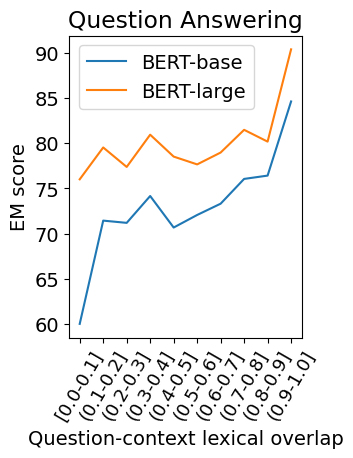
Question answering (QA) models for reading comprehension have been demonstrated to exploit unintended dataset biases such as question-context lexical overlap. This hinders QA models from generalizing to under-represented samples such as questions with low lexical overlap. Question generation (QG), a method for augmenting QA datasets, can be a solution for such performance degradation if QG can properly debias QA datasets. However, we discover that recent neural QG models are biased towards generating questions with high lexical overlap, which can amplify the dataset bias. Moreover, our analysis reveals that data augmentation with these QG models frequently impairs the performance on questions with low lexical overlap, while improving that on questions with high lexical overlap. To address this problem, we use a synonym replacement-based approach to augment questions with low lexical overlap. We demonstrate that the proposed data augmentation approach is simple yet effective to mitigate the degradation problem with only 70k synthetic examples. Our data is publicly available at https://github.com/KazutoshiShinoda/Synonym-Replacement.
翻译:解答问题(QA)模型已被证明是利用非预期的数据集偏差,如问题-文字词汇重叠,这阻碍了QA模型将低词汇重叠问题等样本普遍化为代表性不足的样本,例如低词汇重叠问题。如果QG能够适当地降低QA数据集的偏差,则作为增强QA数据集的一种方法,问题生成可以解决这种性能退化问题。然而,我们发现,最近的神经QG模型偏向于产生高词汇重叠的问题,这可以扩大数据集的偏差。此外,我们的分析表明,与这些QG模型增加数据常常损害低词汇重叠问题的性能,同时改进关于高词汇重叠问题的性能。为解决这一问题,我们使用同义替代方法来补充低词汇重叠问题。我们证明,拟议的数据增强方法简单而有效,只能用70公里的合成示例来缓解退化问题。我们的数据在https://github.com/ Kazutishinoda/Synonym-Replacementment上公开提供。