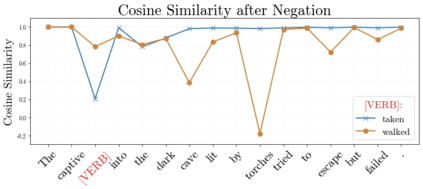
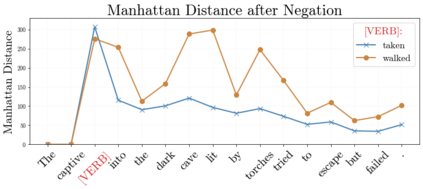
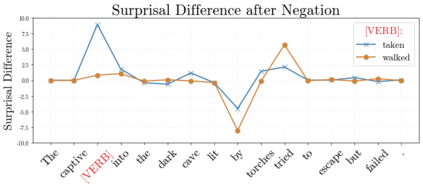
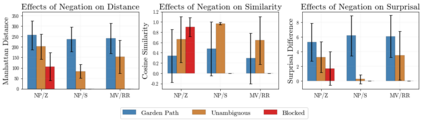
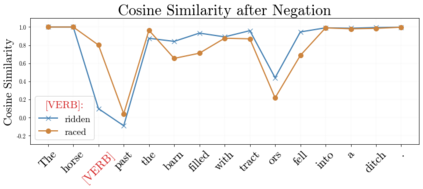
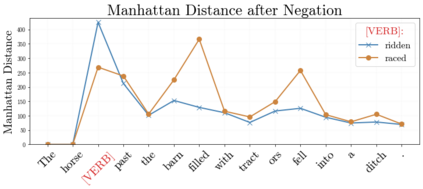
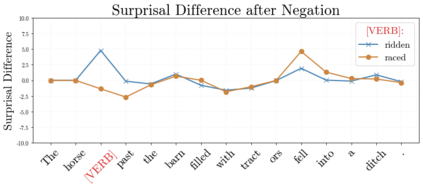
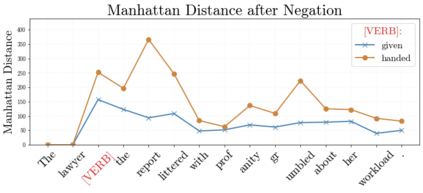
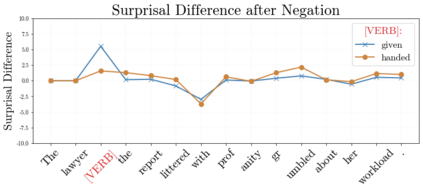
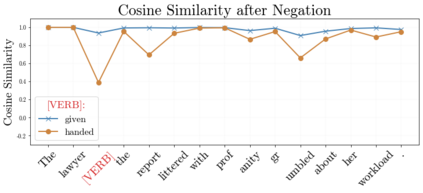
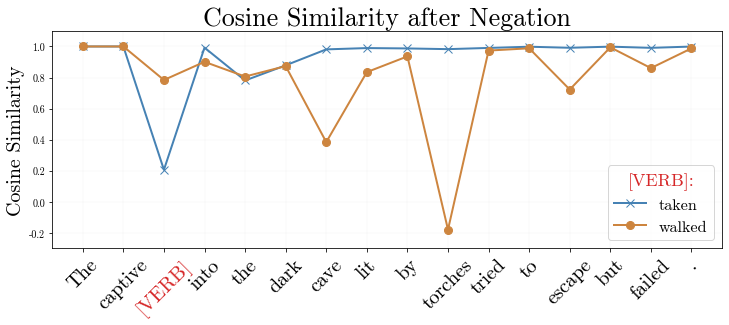
In recent years, large-scale transformer decoders such as the GPT-x family of models have become increasingly popular. Studies examining the behavior of these models tend to focus only on the output of the language modeling head and avoid analysis of the internal states of the transformer decoder. In this study, we present a collection of methods to analyze the hidden states of GPT-2 and use the model's navigation of garden path sentences as a case study. To enable this, we compile the largest currently available dataset of garden path sentences. We show that Manhattan distances and cosine similarities provide more reliable insights compared to established surprisal methods that analyze next-token probabilities computed by a language modeling head. Using these methods, we find that negating tokens have minimal impacts on the model's representations for unambiguous forms of sentences with ambiguity solely over what the object of a verb is, but have a more substantial impact of representations for unambiguous sentences whose ambiguity would stem from the voice of a verb. Further, we find that analyzing the decoder model's hidden states reveals periods of ambiguity that might conclude in a garden path effect but happen not to, whereas surprisal analyses routinely miss this detail.
翻译:近年来,大型变压器解码器,如GPT-x模型系列的GPT-x模型,越来越受欢迎。研究这些模型的行为往往只侧重于语言模型头的输出,避免分析变压器解码器的内部状态。在本研究中,我们提供了一套方法,用来分析GPT-2的隐藏状态,并使用模型对花园路径句子的导航作为案例研究。为了能够做到这一点,我们汇编了目前最大的花园路径句子数据集。我们发现,曼哈顿的距离和相近之处提供了更可靠的洞察力,与分析由语言模型头计算出的下一个图案概率的既定的奇特方法相比。我们发现,用这些方法,变现符号对模型的表达方式影响最小,其明确的句子形式仅含混不清,只针对动词的标语标是什么,但更具有更实质性的影响。我们发现,分析脱coder模型的隐藏状态揭示了一种模糊度的时期,可能得出花园路径的常规分析结果,但不会发生。