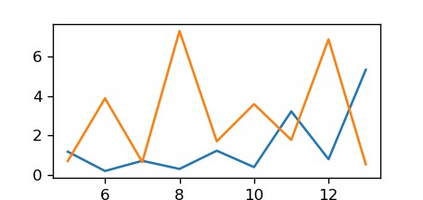
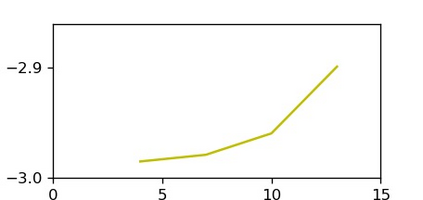
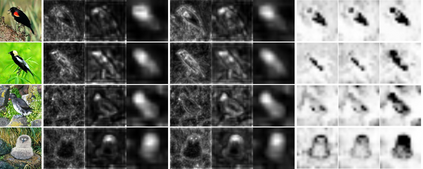
Compared to traditional learning from scratch, knowledge distillation sometimes makes the DNN achieve superior performance. This paper provides a new perspective to explain the success of knowledge distillation, i.e., quantifying knowledge points encoded in intermediate layers of a DNN for classification, based on the information theory. To this end, we consider the signal processing in a DNN as the layer-wise information discarding. A knowledge point is referred to as an input unit, whose information is much less discarded than other input units. Thus, we propose three hypotheses for knowledge distillation based on the quantification of knowledge points. 1. The DNN learning from knowledge distillation encodes more knowledge points than the DNN learning from scratch. 2. Knowledge distillation makes the DNN more likely to learn different knowledge points simultaneously. In comparison, the DNN learning from scratch tends to encode various knowledge points sequentially. 3. The DNN learning from knowledge distillation is often optimized more stably than the DNN learning from scratch. In order to verify the above hypotheses, we design three types of metrics with annotations of foreground objects to analyze feature representations of the DNN, \textit{i.e.} the quantity and the quality of knowledge points, the learning speed of different knowledge points, and the stability of optimization directions. In experiments, we diagnosed various DNNs for different classification tasks, i.e., image classification, 3D point cloud classification, binary sentiment classification, and question answering, which verified above hypotheses.
翻译:与从零开始的传统学习相比, 知识蒸馏有时会让 DNN 取得更高的业绩。 本文提供了一个新的视角来解释知识蒸馏的成功, 即根据信息理论, 量化在 DNN 中间层编码的知识点, 以便分类。 为此, 我们把 DNN 中的信号处理视为分层信息丢弃。 将DNN 中的信号处理称为一个知识点, 其信息比其他输入单位少得多被丢弃。 因此, 我们提出三个基于知识点量化的知识蒸馏假设。 1. DNN 从知识蒸馏中学习的知识点编码比 DNN 从零开始学习的知识点要多。 2 知识蒸馏使 DNN 更有可能同时学习不同的知识点。 相比之下, DNN 从零开始的信号处理过程往往比 DNN 从从零开始的学习更精细。 为了核实上述假设, 我们设计了三种类型的指标, 上面的感化点的感知性说明, Dnoralaldald livealation 3 。