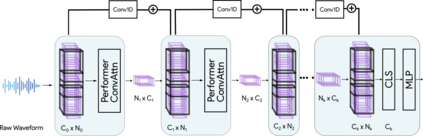
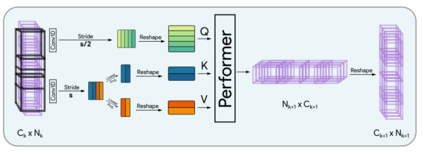
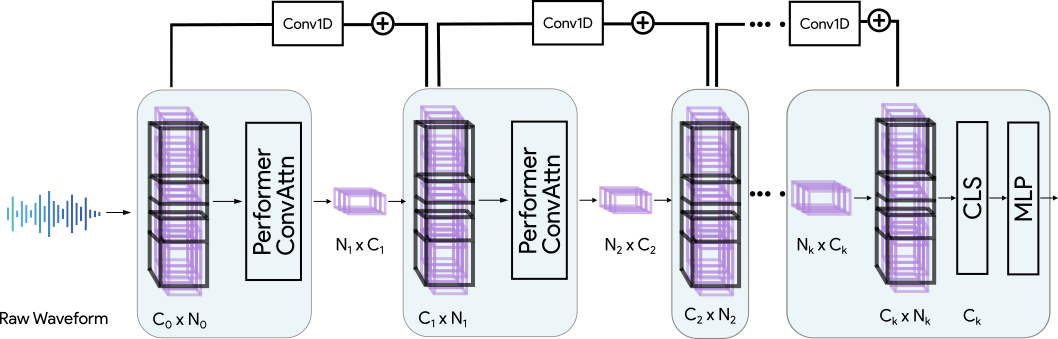
Transformers have seen an unprecedented rise in Natural Language Processing and Computer Vision tasks. However, in audio tasks, they are either infeasible to train due to extremely large sequence length of audio waveforms or reach competitive performance after feature extraction through Fourier-based methods, incurring a loss-floor. In this work, we introduce an architecture, Audiomer, where we combine 1D Residual Networks with Performer Attention to achieve state-of-the-art performance in Keyword Spotting with raw audio waveforms, out-performing all previous methods while also being computationally cheaper, much more parameter and data-efficient. Audiomer allows for deployment in compute-constrained devices and training on smaller datasets.
翻译:然而,在音频任务中,由于音频波形的序列长度非常之大,或者在通过基于Fourier的方法进行地貌提取后达到竞争性性能,从而造成损失。 在这项工作中,我们引入了一个架构,即1D残余网络与表演者关注结合起来,在关键字中实现最先进的性能,即与原始音频波形相匹配,优于以往所有方法,同时计算成本低、参数高得多、数据效率高。 音频可以部署在计算受限制的装置和较小数据集的培训中。