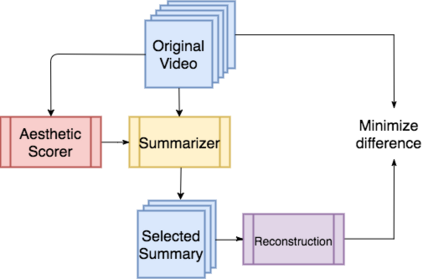
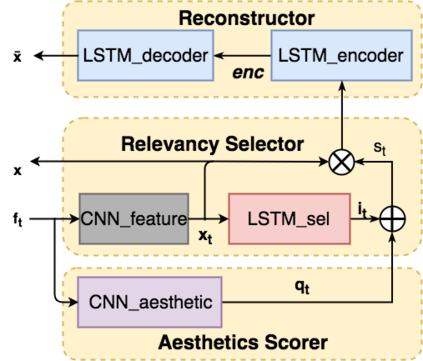
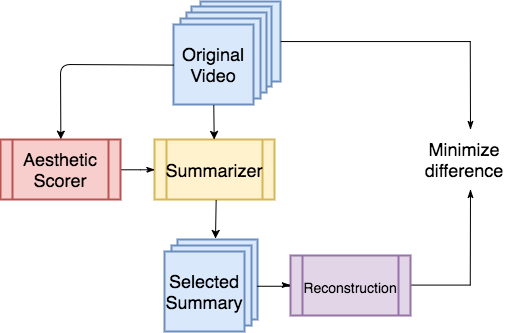
Video summaries come in many forms, from traditional single-image thumbnails, animated thumbnails, storyboards, to trailer-like video summaries. Content creators use the summaries to display the most attractive portion of their videos; the users use them to quickly evaluate if a video is worth watching. All forms of summaries are essential to video viewers, content creators, and advertisers. Often video content management systems have to generate multiple versions of summaries that vary in duration and presentational forms. We present a framework ReconstSum that utilizes LSTM-based autoencoder architecture to extract and select a sparse subset of video frames or keyshots that optimally represent the input video in an unsupervised manner. The encoder selects a subset from the input video while the decoder seeks to reconstruct the video from the selection. The goal is to minimize the difference between the original input video and the reconstructed video. Our method is easily extendable to generate a variety of applications including static video thumbnails, animated thumbnails, storyboards and "trailer-like" highlights. We specifically study and evaluate two most popular use cases: thumbnail generation and storyboard generation. We demonstrate that our methods generate better results than the state-of-the-art techniques in both use cases.
翻译:视频摘要以多种形式出现, 从传统的单一图像缩略图、动画缩略图、故事版到拖动式视频摘要。 内容创建者使用摘要来显示其视频中最有吸引力的部分; 用户使用摘要来快速评估视频是否值得观看。 所有形式的摘要对于视频浏览者、 内容创建者和广告商至关重要。 通常视频内容管理系统必须生成不同时间和演示形式的多版摘要。 我们提出了一个框架 ReconstSum, 利用基于 LSTM 的自动编码结构来提取和选择稀有的一组视频框架或关键片, 以不受监督的方式最佳地代表输入视频。 编码器从输入视频中选择一个子片段, 而解译器则试图从选择中重建视频。 目标是尽可能缩小原始输入视频和再版视频之间的差别。 我们的方法很容易扩展, 以产生多种应用, 包括静态视频缩略图、 模拟缩略图、 故事板和“ 易变缩图” 亮图。 我们专门研究并评估了两种最流行的生成方法: 我们使用最流行的生成方法, 以及最常用的生成案例。 我们具体地使用了两个缩略图案例, 使用了两种方法, 并评估了两种方法, 都使用了两种方法。