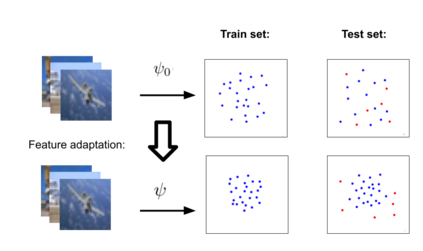
Anomaly detection methods require high-quality features. In recent years, the anomaly detection community has attempted to obtain better features using advances in deep self-supervised feature learning. Surprisingly, a very promising direction, using pretrained deep features, has been mostly overlooked. In this paper, we first empirically establish the perhaps expected, but unreported result, that combining pretrained features with simple anomaly detection and segmentation methods convincingly outperforms, much more complex, state-of-the-art methods. In order to obtain further performance gains in anomaly detection, we adapt pretrained features to the target distribution. Although transfer learning methods are well established in multi-class classification problems, the one-class classification (OCC) setting is not as well explored. It turns out that naive adaptation methods, which typically work well in supervised learning, often result in catastrophic collapse (feature deterioration) and reduce performance in OCC settings. A popular OCC method, DeepSVDD, advocates using specialized architectures, but this limits the adaptation performance gain. We propose two methods for combating collapse: i) a variant of early stopping that dynamically learns the stopping iteration ii) elastic regularization inspired by continual learning. Our method, PANDA, outperforms the state-of-the-art in the OCC, outlier exposure and anomaly segmentation settings by large margins.
翻译:异常探测方法需要高质量的特征。 近年来,异常检测社区试图利用深层自我监督特征学习的进步来获得更好的特征。 令人惊讶的是, 使用预先训练的深层特征的极有希望的方向被忽略了。 在本文件中,我们首先以经验方式确定了可能预期但未报告的结果, 将预先训练的特征与简单异常检测和分解方法相结合, 令人信服地优于优异, 远为复杂, 最先进的方法。 为了在异常检测中获得进一步的绩效收益, 我们根据目标分布调整了预先训练的特征。 尽管在多级分类问题上已经很好地确立了转移学习方法, 但单级分类设置并没有很好地探索。 事实证明,在监督的学习中通常行之有效的天真的适应方法往往导致灾难性的崩溃( 地貌恶化), 并降低OCC环境的性能。 流行的OCC方法, DeepSVDD, 提倡使用专门的架构, 但却限制了适应性绩效的增益。 我们提出了两种打击崩溃的方法 : i) 早期阻止这种转变, 快速地学会在大等级结构中停止我们不断学习的方法。