
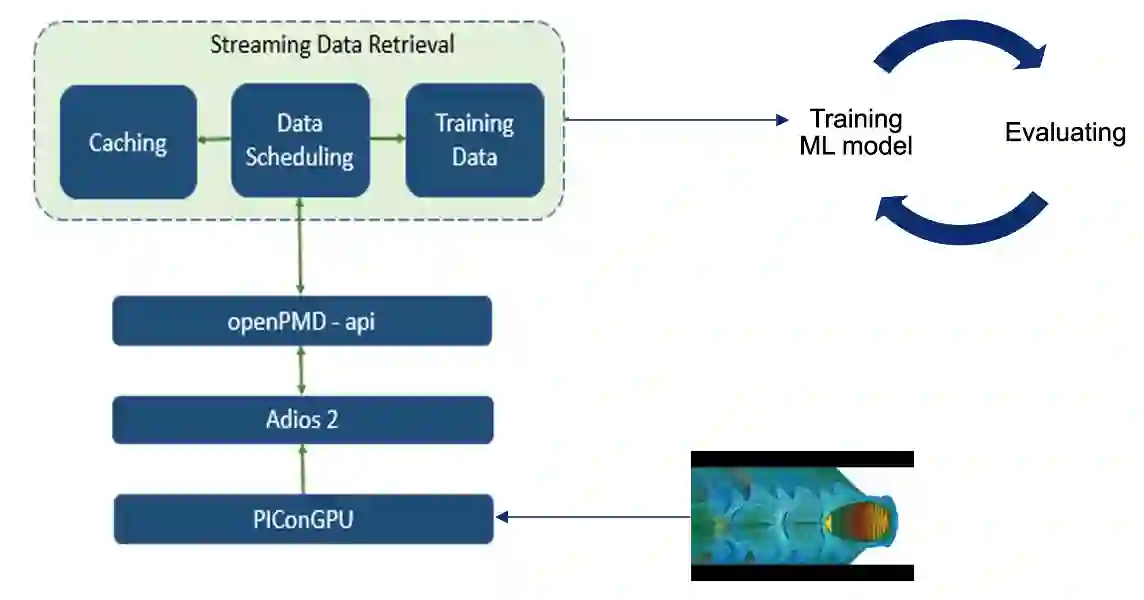
The upcoming exascale era will provide a new generation of physics simulations. These simulations will have a high spatiotemporal resolution, which will impact the training of machine learning models since storing a high amount of simulation data on disk is nearly impossible. Therefore, we need to rethink the training of machine learning models for simulations for the upcoming exascale era. This work presents an approach that trains a neural network concurrently to a running simulation without storing data on a disk. The training pipeline accesses the training data by in-memory streaming. Furthermore, we apply methods from the domain of continual learning to enhance the generalization of the model. We tested our pipeline on the training of a 3d autoencoder trained concurrently to laser wakefield acceleration particle-in-cell simulation. Furthermore, we experimented with various continual learning methods and their effect on the generalization.
翻译:即将到来的显微时代将提供新一代的物理模拟。 这些模拟将具有高度的时空分辨率,这将影响机器学习模型的培训,因为将大量模拟数据储存在磁盘上几乎是不可能的。 因此,我们需要重新思考为即将到来的显微时代进行模拟的机器学习模型的培训。 这项工作提出了一种方法,即对神经网络进行培训,同时进行模拟,而不将数据储存在磁盘上。 培训管道通过模拟流进入培训数据。 此外,我们从持续学习的领域应用各种方法来提高模型的普及性。 我们测试了我们训练的三维自动电解器的管道,同时培训了激光休克加速细胞内粒子模拟。 此外,我们还试验了各种持续学习方法及其对一般化的影响。

相关内容

Source: Apple - iOS 8


