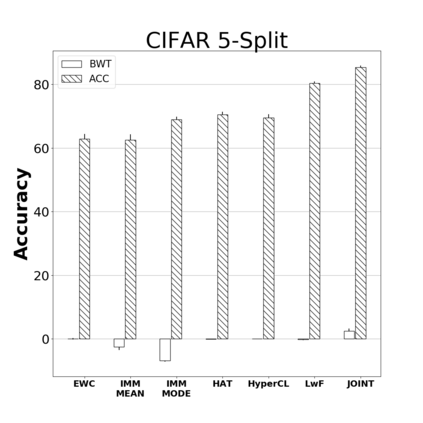
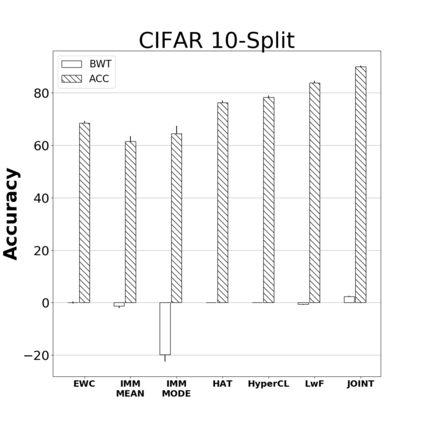
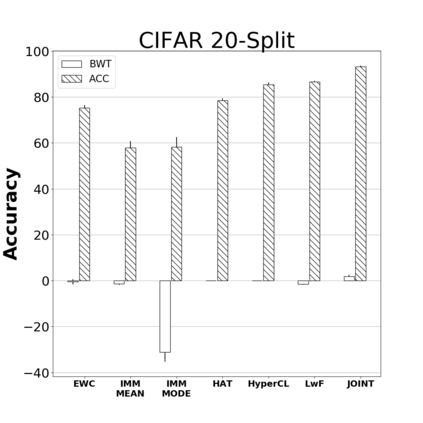
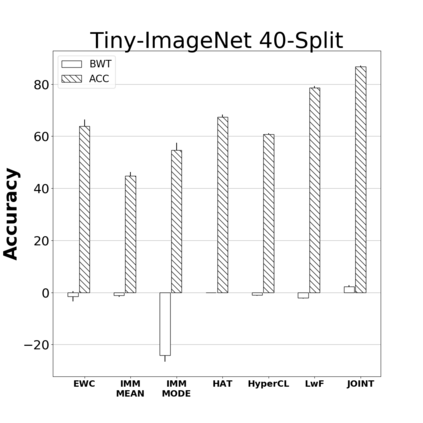
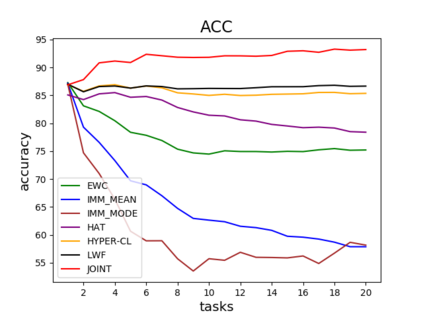
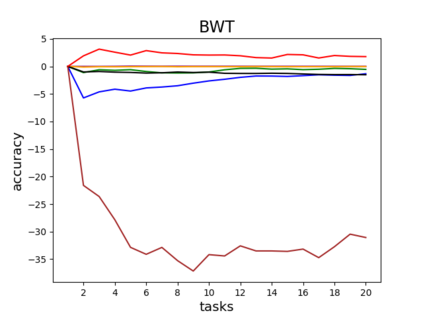
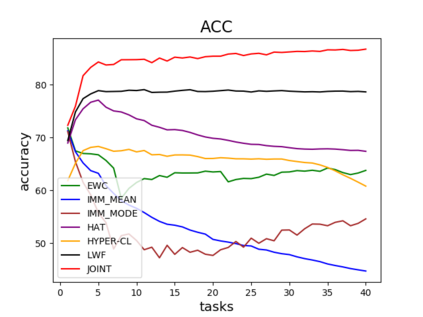
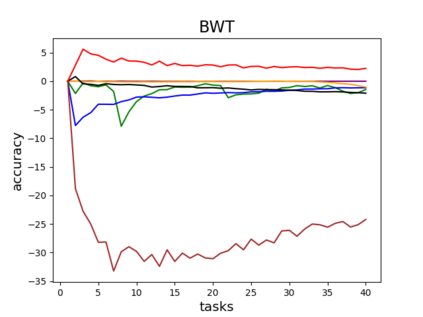
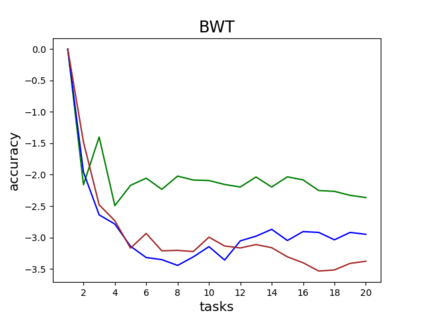
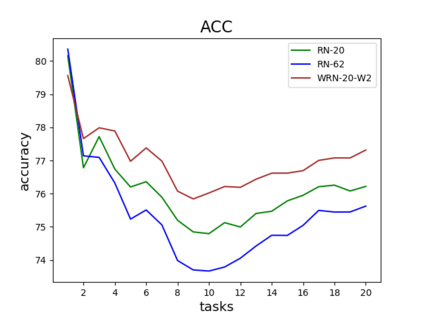
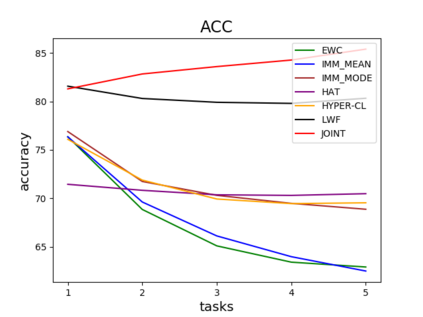
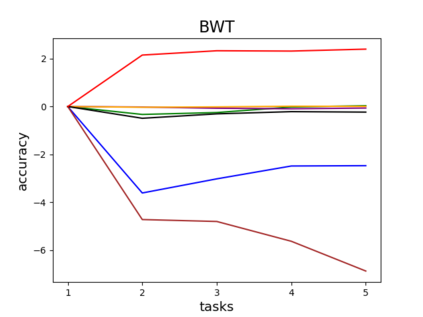
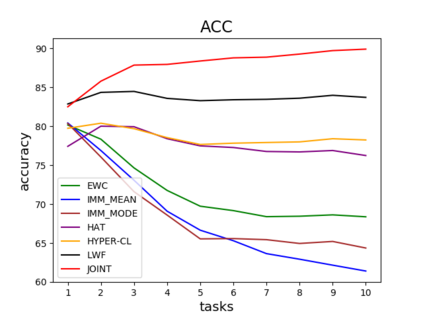
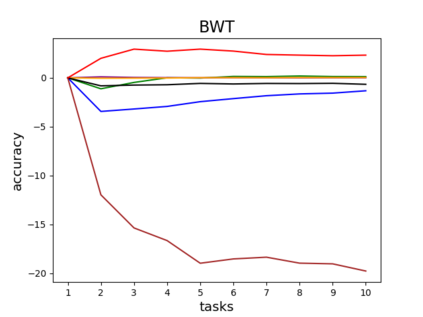
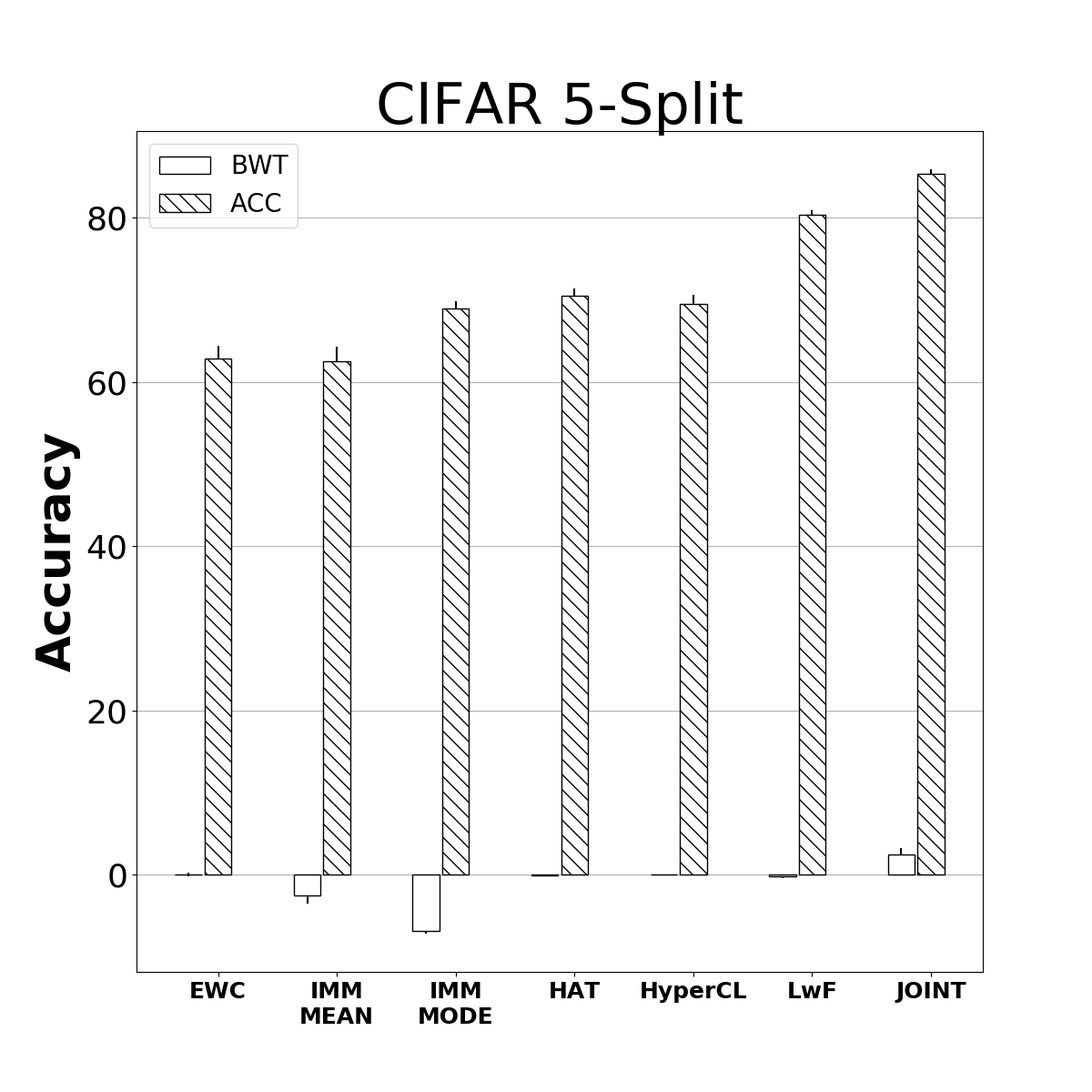
Catastrophic forgetting is one of the major challenges on the road for continual learning systems, which are presented with an on-line stream of tasks. The field has attracted considerable interest and a diverse set of methods have been presented for overcoming this challenge. Learning without Forgetting (LwF) is one of the earliest and most frequently cited methods. It has the advantages of not requiring the storage of samples from the previous tasks, of implementation simplicity, and of being well-grounded by relying on knowledge distillation. However, the prevailing view is that while it shows a relatively small amount of forgetting when only two tasks are introduced, it fails to scale to long sequences of tasks. This paper challenges this view, by showing that using the right architecture along with a standard set of augmentations, the results obtained by LwF surpass the latest algorithms for task incremental scenario. This improved performance is demonstrated by an extensive set of experiments over CIFAR-100 and Tiny-ImageNet, where it is also shown that other methods cannot benefit as much from similar improvements.
翻译:连续学习系统道路上的主要挑战之一是灾难性的忘却,而这种系统是在线的任务流。这个领域吸引了相当大的兴趣,为克服这一挑战提出了各种各样的方法。不忘(LwF)的学习是最早和最经常引用的方法之一。它的好处是,不要求储存以前任务的样本,不要求执行的简单,也不要求依靠知识的蒸馏而有良好的基础。但是,普遍的看法是,虽然它显示在只引入两项任务时,忘记的数量相对较少,但却没有达到任务的长期顺序。本文挑战了这一观点,表明使用正确的结构以及一套标准的扩大,LwF取得的结果超过了任务递增情景的最新算法。通过对CIFAR-100和Tiny-ImageNet的广泛试验,也表明其他方法无法从类似的改进中获益。