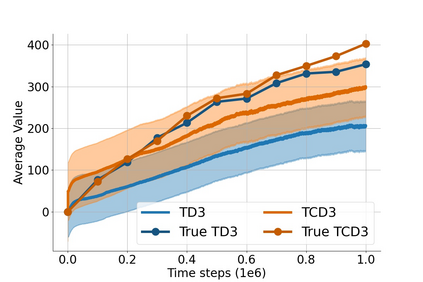
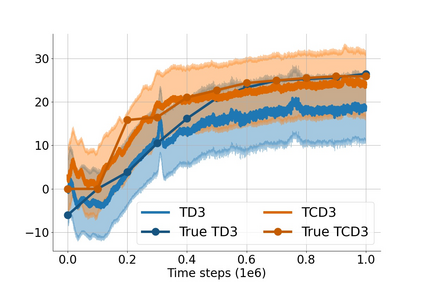
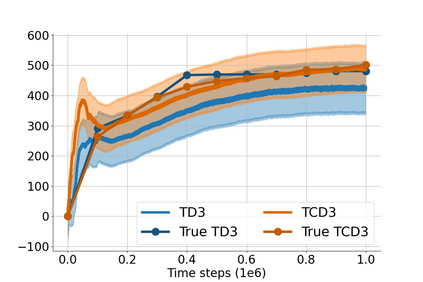
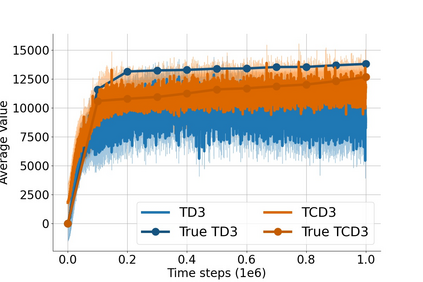
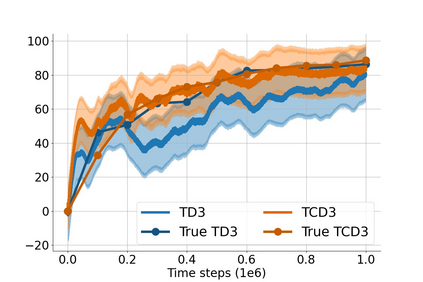
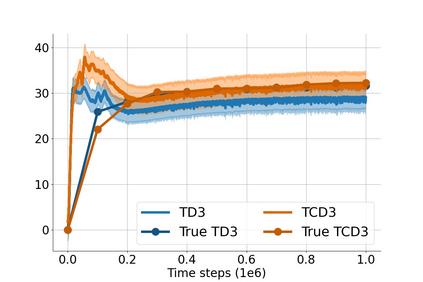
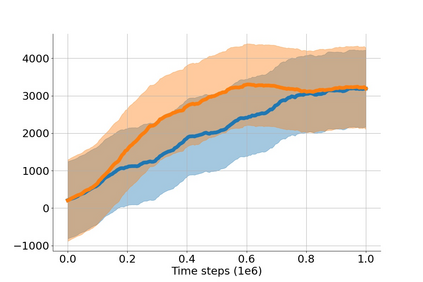
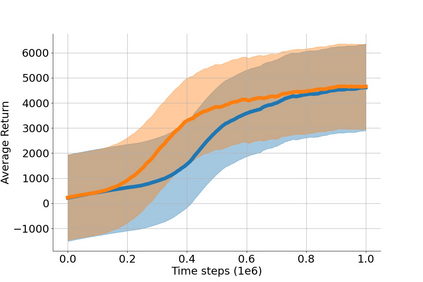
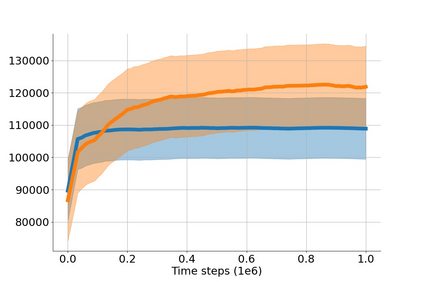
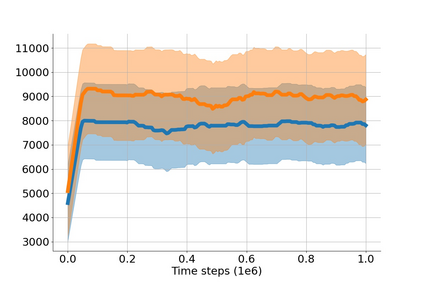
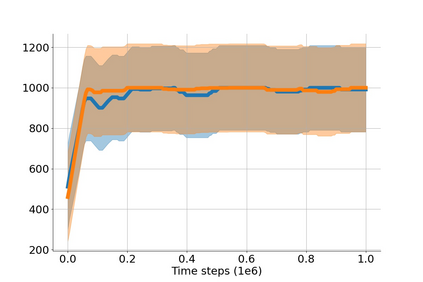
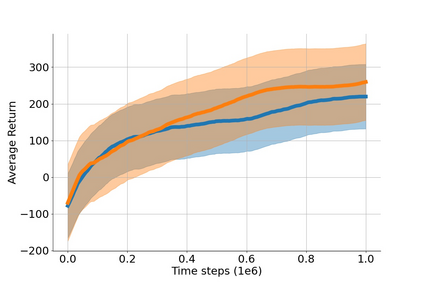
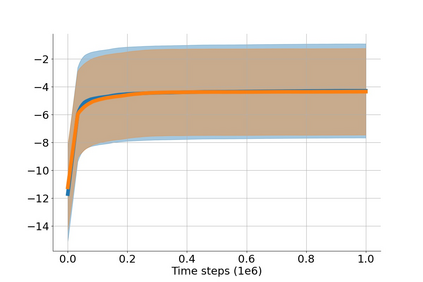
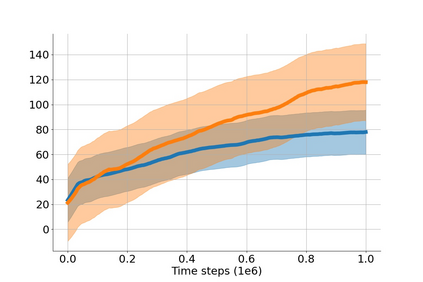
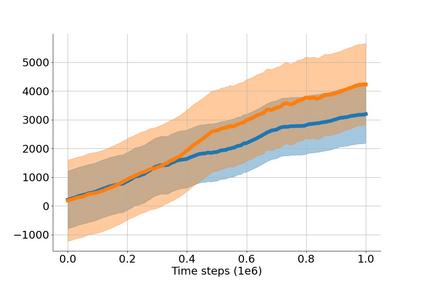
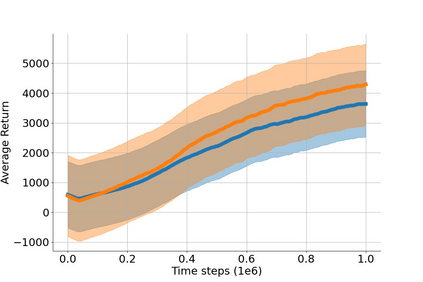
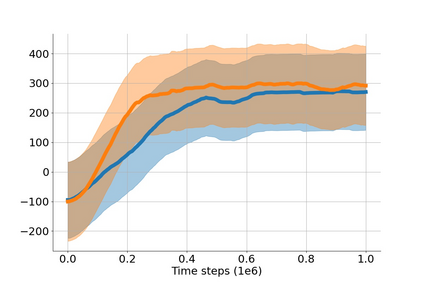
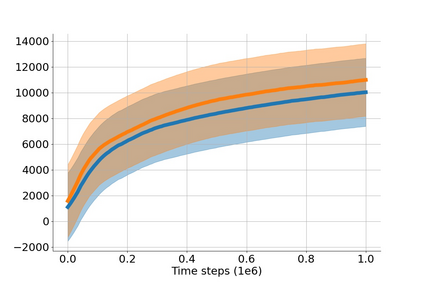
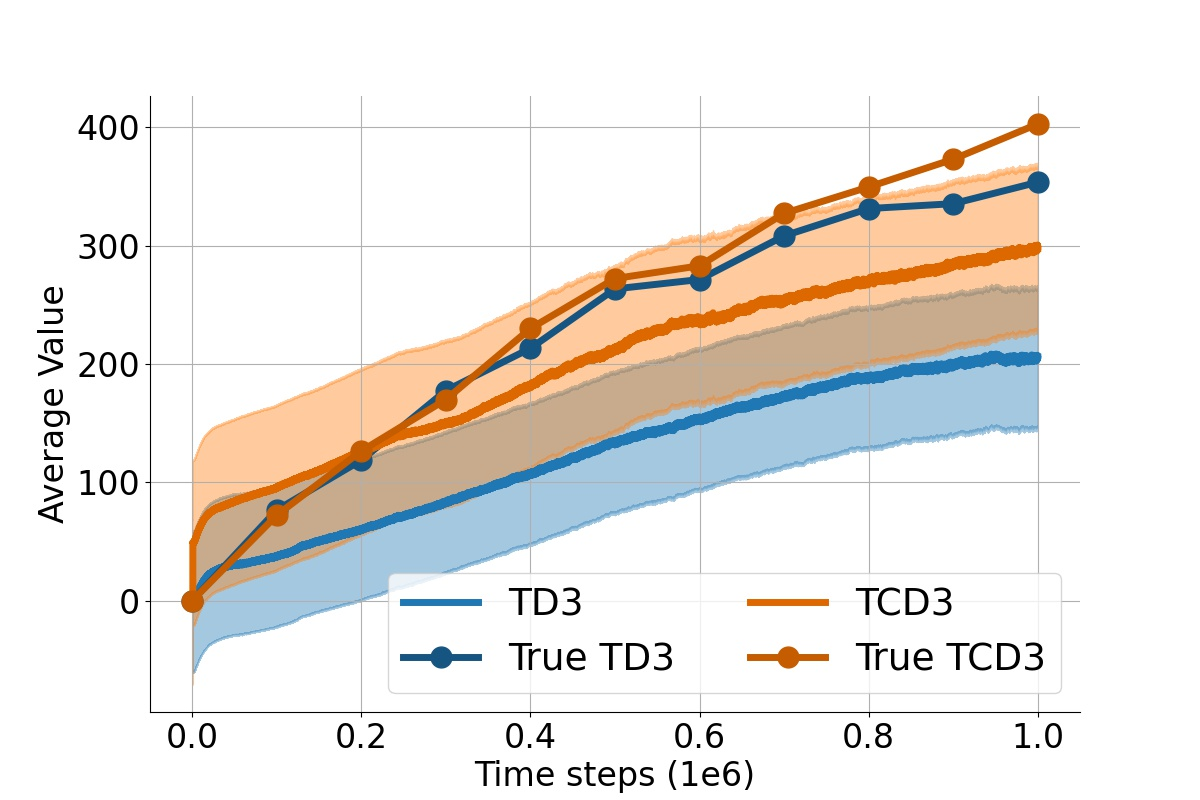
In value-based deep reinforcement learning methods, approximation of value functions induces overestimation bias and leads to suboptimal policies. We show that in deep actor-critic methods that aim to overcome the overestimation bias, if the reinforcement signals received by the agent have a high variance, a significant underestimation bias arises. To minimize the underestimation, we introduce a parameter-free, novel deep Q-learning variant. Our Q-value update rule combines the notions behind Clipped Double Q-learning and Maxmin Q-learning by computing the critic objective through the nested combination of maximum and minimum operators to bound the approximate value estimates. We evaluate our modification on the suite of several OpenAI Gym continuous control tasks, improving the state-of-the-art in every environment tested.
翻译:在基于价值的深层强化学习方法中,价值函数近似值会引起高估偏差,并导致低于最佳的政策。我们表明,在旨在克服高估偏差的深层次行为者-批评方法中,如果代理人收到的增强信号存在很大差异,就会出现重大的低估偏差。为了尽量减少低估,我们引入了一个无参数的、新的深层次Q学习变体。我们的Q值更新规则结合了Clipped 双Q学习和Maxmin Q学习背后的概念,通过最大和最低操作者的嵌套组合来计算批评目标,以约束近似价值估计。我们评估了我们对几个OpenAI Gym连续控制任务的套件的修改,改进了每个测试环境中的最新技术。