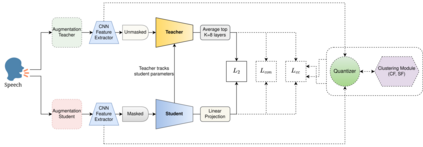
In this paper, we propose a new Self-Supervised Learning (SSL) algorithm called data2vec-aqc, for speech representation learning from unlabeled speech data. Our goal is to improve SSL for speech in domains where both unlabeled and labeled data are limited. Building on the recently introduced data2vec, we introduce additional modules to the data2vec framework that leverage the benefit of data augmentations, quantized representations, and clustering. The interaction between these modules helps solve the cross-contrastive loss as an additional self-supervised objective. data2vec-aqc achieves up to 14.1% and 20.9% relative WER improvement over the existing state-of-the-art data2vec system on the test-clean and test-other sets, respectively, of LibriSpeech, without the use of any language model. Our proposed model also achieves up to 17.8% relative WER improvement over the baseline data2vec when fine-tuned on Switchboard data.
翻译:在本文中,我们提出一个新的“自我监督学习”算法,名为“数据2vec-aqc”,用于从未贴标签的语音数据中学习语音演示。我们的目标是在未贴标签和标签的数据都有限的领域改进语音的 SSL 。根据最近引入的数据2vec,我们为数据2vec 框架引入了额外的模块,以利用数据增强、量化的表达和集成的好处。这些模块之间的相互作用有助于解决交叉争议损失,作为另一个自我监督的目标。数据2vec-aqc 实现了对LibriSpeech测试-peech测试-其他系统的现有最新数据2vec系统的14.1%和20.9%相对WER的改进,而没有使用任何语言模型。在对切换板数据进行微调时,我们提议的模型也实现了比基线数据2vec的17.8%的相对WER改进。