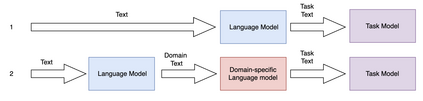
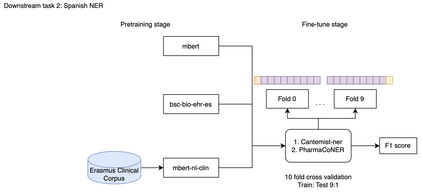
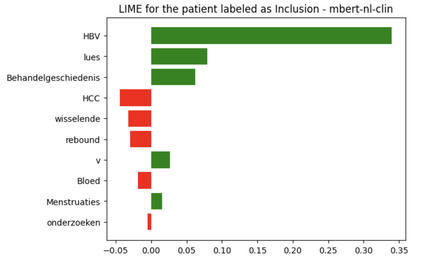
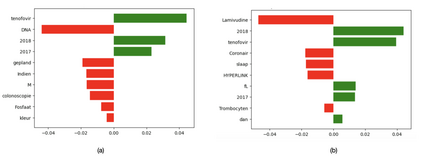
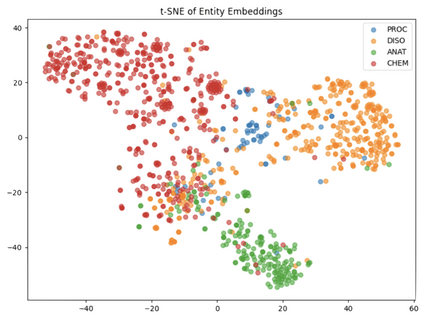
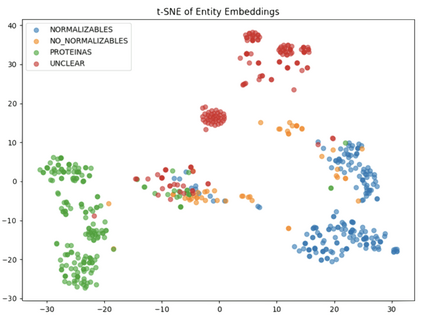
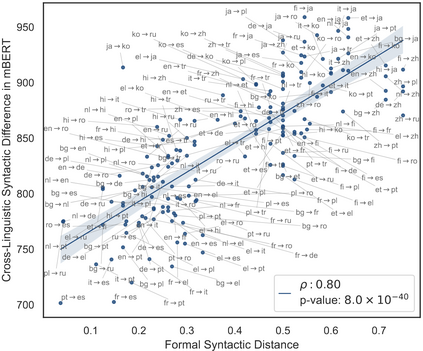
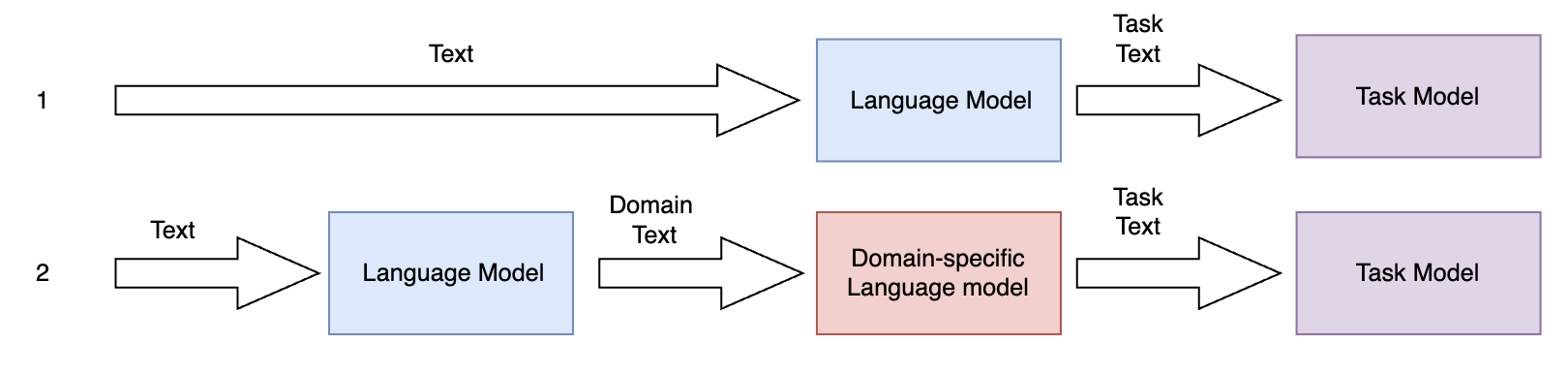
In multilingual healthcare applications, the availability of domain-specific natural language processing(NLP) tools is limited, especially for low-resource languages. Although multilingual bidirectional encoder representations from transformers (BERT) offers a promising motivation to mitigate the language gap, the medical NLP tasks in low-resource languages are still underexplored. Therefore, this study investigates how further pre-training on domain-specific corpora affects model performance on medical tasks, focusing on three languages: Dutch, Romanian and Spanish. In terms of further pre-training, we conducted four experiments to create medical domain models. Then, these models were fine-tuned on three downstream tasks: Automated patient screening in Dutch clinical notes, named entity recognition in Romanian and Spanish clinical notes. Results show that domain adaptation significantly enhanced task performance. Furthermore, further differentiation of domains, e.g. clinical and general biomedical domains, resulted in diverse performances. The clinical domain-adapted model outperformed the more general biomedical domain-adapted model. Moreover, we observed evidence of cross-lingual transferability. Moreover, we also conducted further investigations to explore potential reasons contributing to these performance differences. These findings highlight the feasibility of domain adaptation and cross-lingual ability in medical NLP. Within the low-resource language settings, these findings can provide meaningful guidance for developing multilingual medical NLP systems to mitigate the lack of training data and thereby improve the model performance.
翻译:暂无翻译