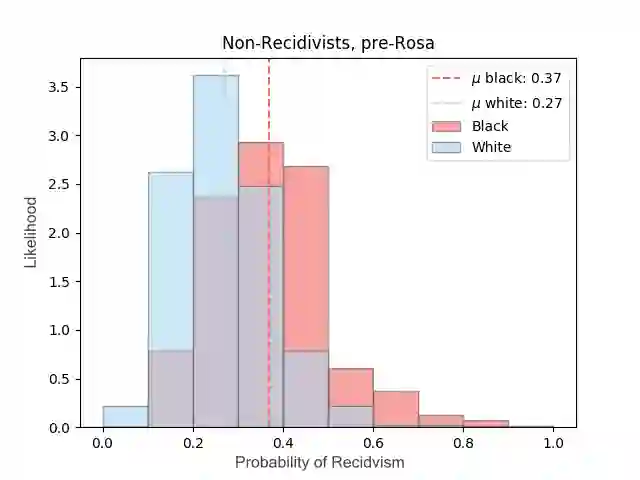
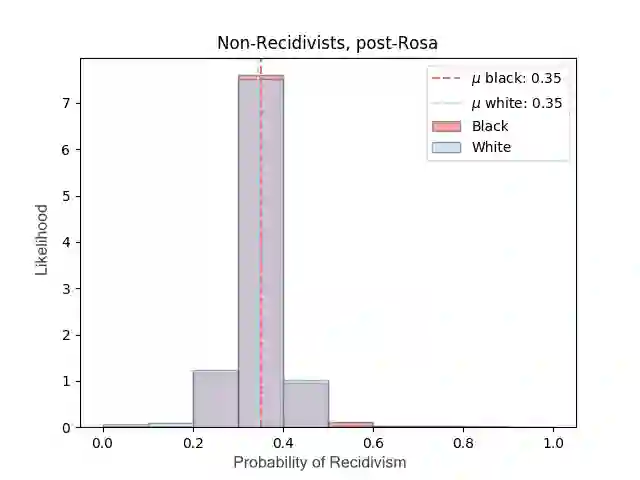
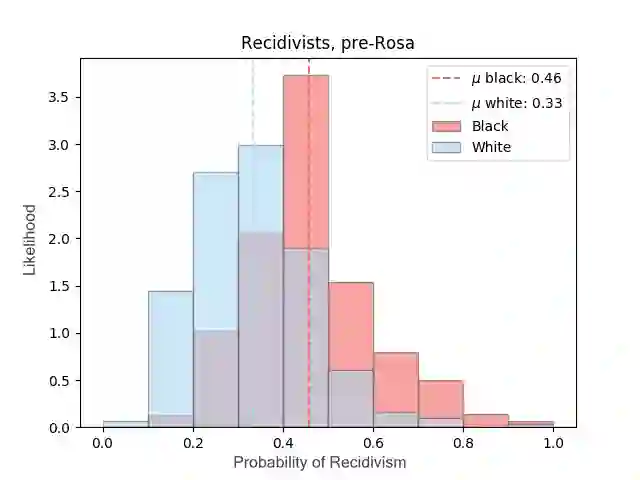
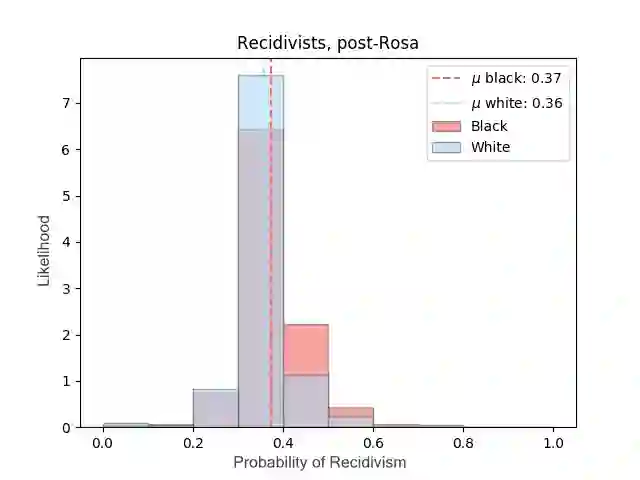
Most datasets of interest to the analytics industry are impacted by various forms of human bias. The outcomes of Data Analytics [DA] or Machine Learning [ML] on such data are therefore prone to replicating the bias. As a result, a large number of biased decision-making systems based on DA/ML have recently attracted attention. In this paper we introduce Rosa, a free, web-based tool to easily de-bias datasets with respect to a chosen characteristic. Rosa is based on the principles of Fair Adversarial Networks, developed by illumr Ltd., and can therefore remove interactive, non-linear, and non-binary bias. Rosa is stand-alone pre-processing step / API, meaning it can be used easily with any DA/ML pipeline. We test the efficacy of Rosa in removing bias from data-driven decision making systems by performing standard DA tasks on five real-world datasets, selected for their relevance to current DA problems, and also their high potential for bias. We use simple ML models to model a characteristic of analytical interest, and compare the level of bias in the model output both with and without Rosa as a pre-processing step. We find that in all cases there is a substantial decrease in bias of the data-driven decision making systems when the data is pre-processed with Rosa.
翻译:分析行业感兴趣的大多数数据集都受到人类偏见的各种形式的影响。因此,数据分析(DA)或机器学习(ML)关于这些数据的结果很容易复制这种偏见。结果,大量基于DA/ML的有偏见的决策系统最近引起注意。在本文中,我们介绍罗莎,这是一个免费的网络工具,可以很容易地降低与所选特征有关的数据。罗莎是基于由Idrumr有限公司开发的公平对立网络的原则,因此可以消除互动性、非线性和非双向性偏差。罗莎是独立的处理前步骤/API,这意味着它很容易在任何DA/ML管道中使用。我们测试罗莎在消除数据驱动决策系统偏差方面的效力,通过五个真实世界数据集执行标准的DA任务,根据它们与当前DA问题的相关性选择,以及它们具有高度的偏向性。我们使用简单的ML模型来模拟分析兴趣特征,并将模型中偏向偏向程度与模型处理前的偏向程度进行比较。我们发现,在模型处理过程中,在模型处理前,我们发现所有数据偏向前的偏向性是罗莎,我们发现,在模型中发现,在模型处理前的偏向前是显著。