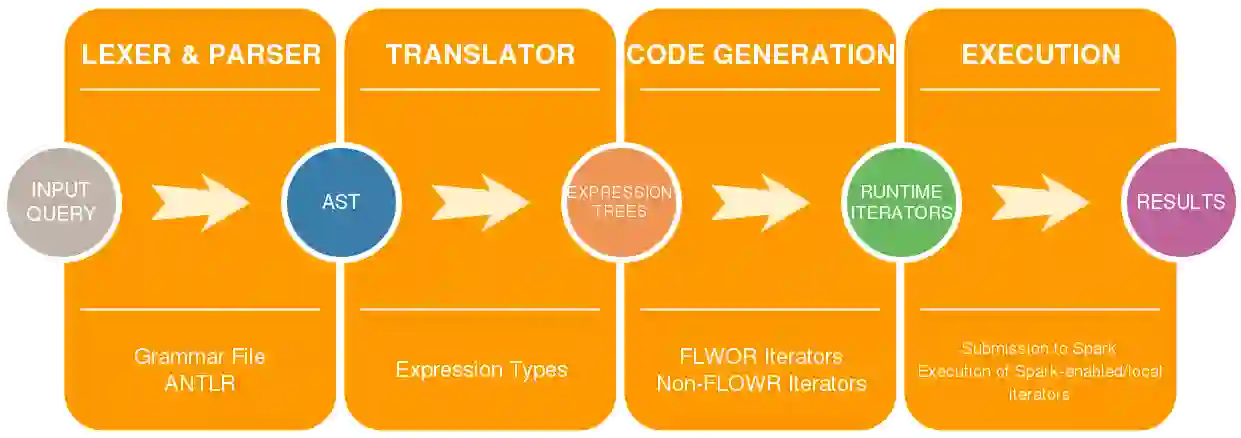
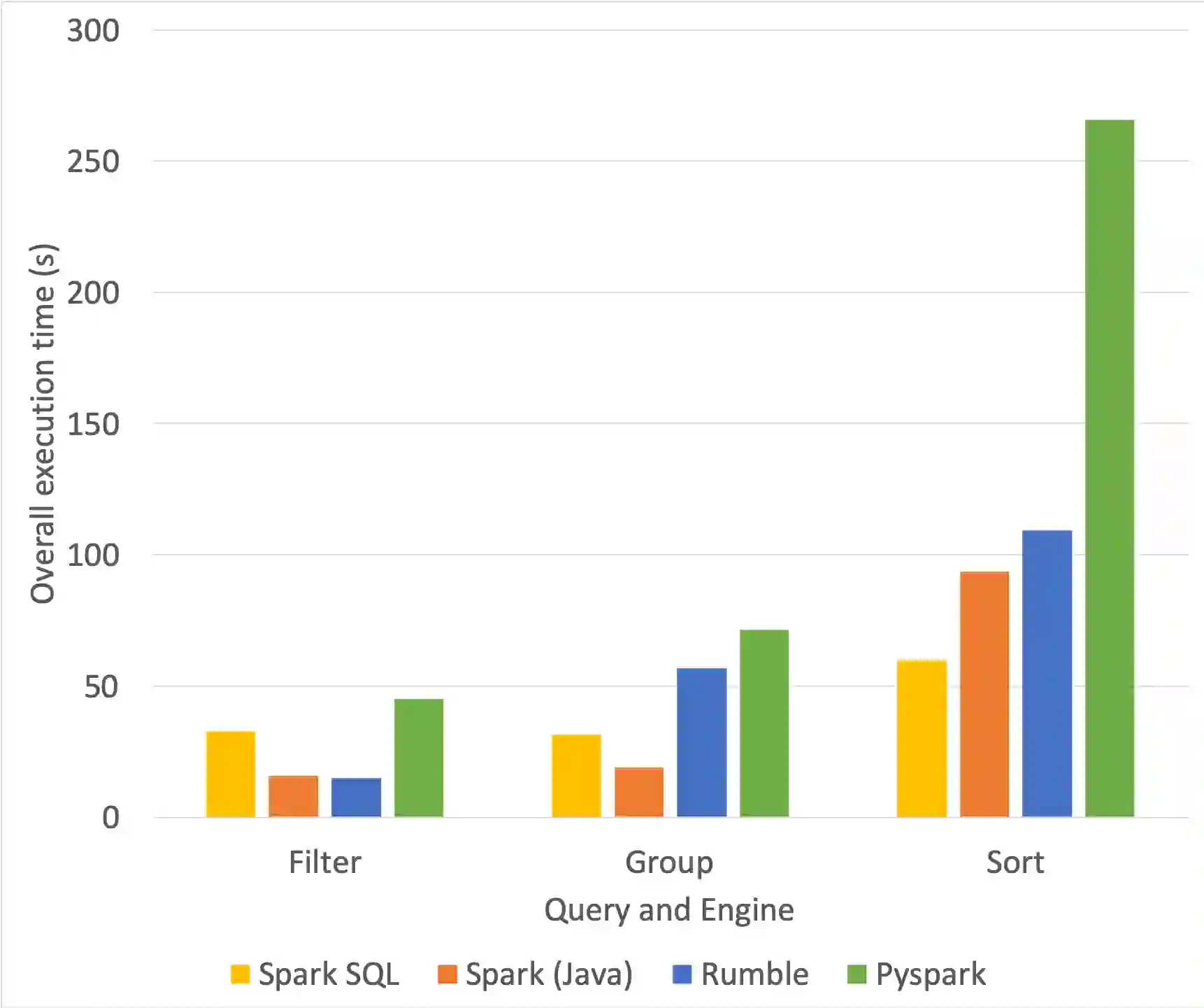
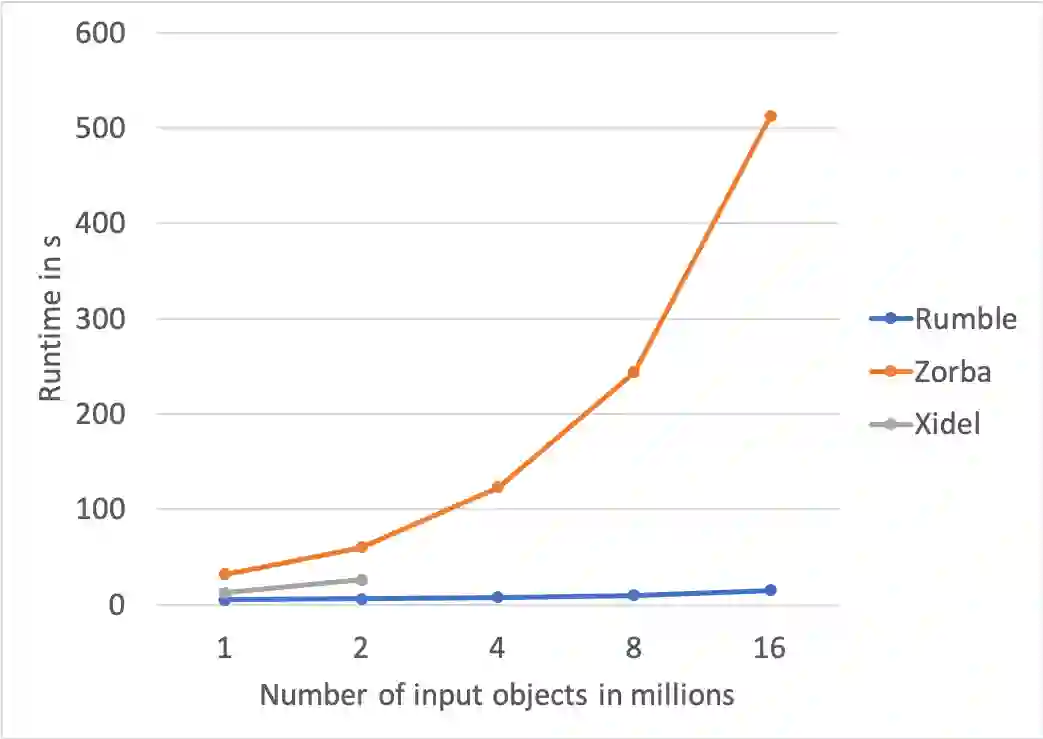
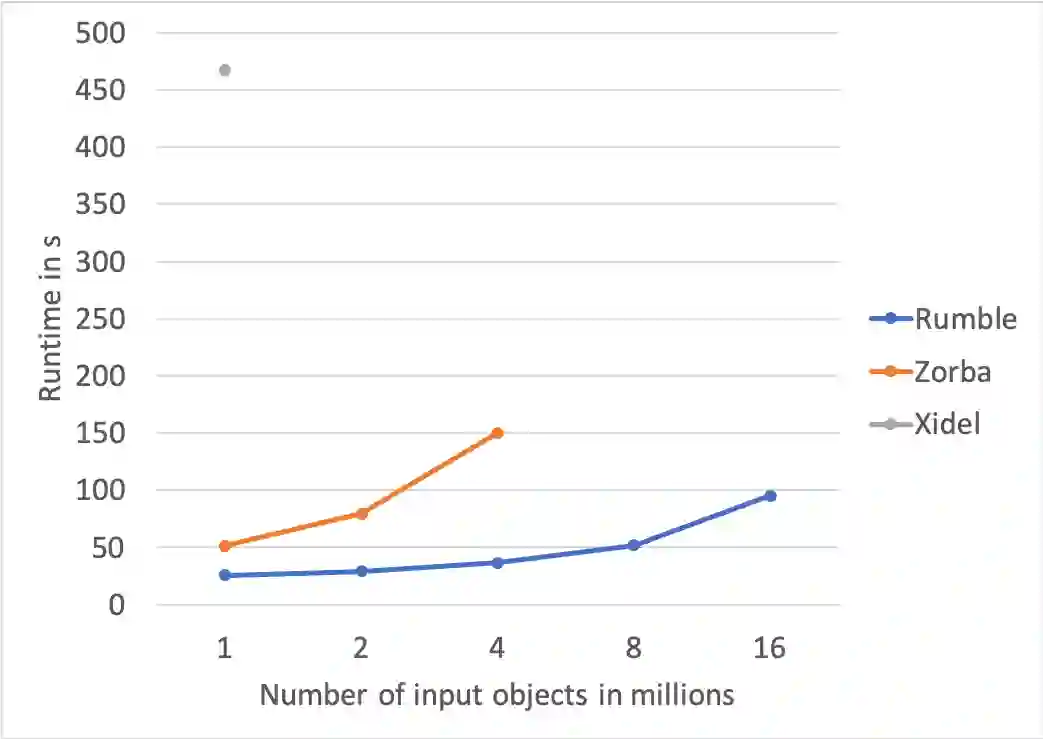
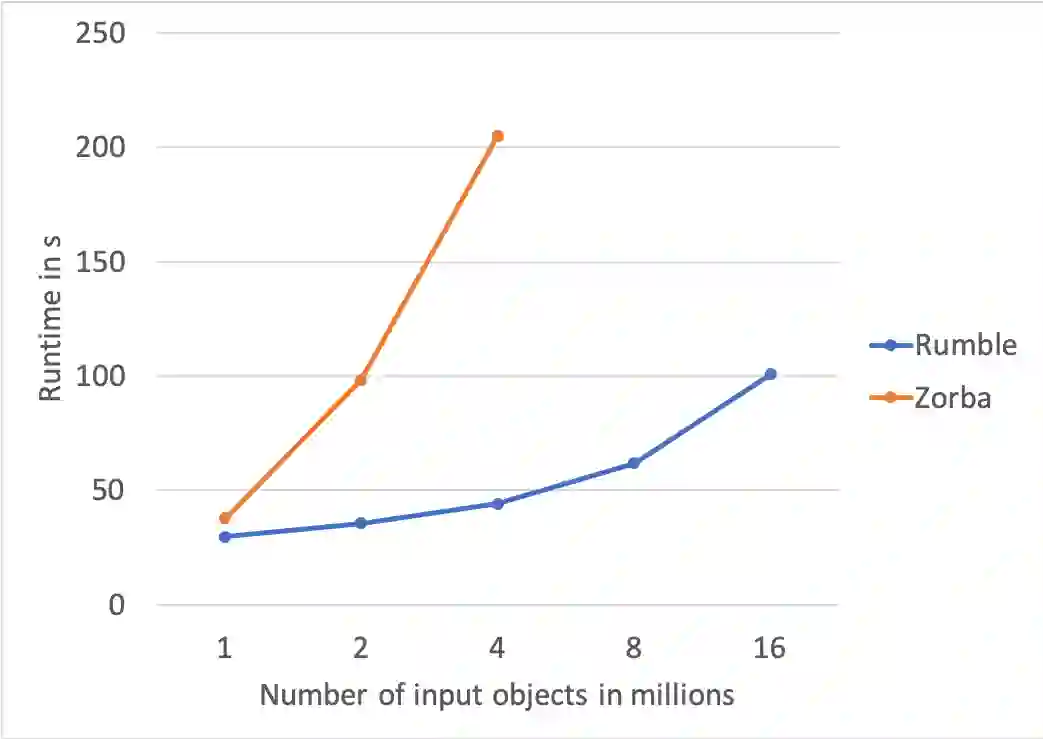
This paper introduces Rumble, an engine that executes JSONiq queries on large, heterogenous and nested collections of JSON objects, leveraging the parallel capabilities of Spark so as to provide a high degree of data independence. The design is based on two key insights: (i) how to map JSONiq expressions to Spark transformations on RDDs and (ii) how to map JSONiq FLWOR clauses to Spark SQL on DataFrames. We have developed a working implementation of these mappings showing that JSONiq can efficiently run on Spark to query billions of objects into, at least, the TB range. The JSONiq code is concise in comparison to Spark's host languages while seamlessly supporting the nested, heterogeneous datasets that Spark SQL does not. The ability to process this kind of input, commonly found, is paramount for data cleaning and curation. The experimental analysis indicates that there is no excessive performance loss, occasionally even a gain, over Spark SQL for structured data, and a performance gain over PySpark. This demonstrates that a language such as JSONiq is a simple and viable approach to large-scale querying of denormalized, heterogeneous, arborescent datasets, in the same way as SQL can be leveraged for structured datasets. The results also illustrate that Codd's concept of data independence makes as much sense for heterogeneous, nested datasets as it does on highly structured tables.
翻译:本文介绍Rumble, 这个引擎将 Jsoniniq 询问大型、 杂交和嵌套的 JSonson 对象的收集, 利用 Spark 的平行能力, 以提供高度的数据独立性。 设计基于两个关键洞察力 : (一) 如何将 JSoniq 表达式映射成 RDDs 的闪烁变换, (二) 如何将 JSoniq FLWOR 条款映射成数据清理和校正调。 我们开发了这些绘图的工作性实施方法, 显示 JSoniq 可以在火花上有效运行, 将数十亿天天天天体的天体查询到, 至少在TB 范围。 Jsoniq 代码与Spark 的主体语言相比是简洁的, 同时支持Spark SQL 的嵌套式、 混合的数据集。 通常发现, 处理这种输入的能力对于数据清理和整理至关重要。 实验性分析表明, 在结构化数据表上没有过度的性损失, 有时甚至增益,, 在结构化的SQL 上, 以及性数据在结构化的解算方法上, 。