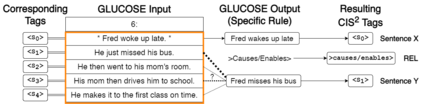
Transformers have been showing near-human performance on a variety of tasks, but they are not without their limitations. We discuss the issue of conflating results of transformers that are instructed to do multiple tasks simultaneously. In particular, we focus on the domain of commonsense reasoning within story prose, which we call contextual commonsense inference (CCI). We look at the GLUCOSE (Mostafazadeh et al. 2020) dataset and task for predicting implicit commonsense inferences between story sentences. Since the GLUCOSE task simultaneously generates sentences and predicts the CCI relation, there is a conflation in the results. Is the model really measuring CCI or is its ability to generate grammatical text carrying the results? In this paper, we introduce the task contextual commonsense inference in sentence selection ($\textsc{CIS}^2}), a simplified task that avoids conflation by eliminating language generation altogether. Our findings emphasize the necessity of future work to disentangle language generation from the desired NLP tasks at hand.
翻译:变异器在各种任务上表现出近乎人性的性能,但并非没有限制。 我们讨论了同时执行多项任务的变异器合并结果的问题。 特别是, 我们注重故事文稿中的常识推理领域, 我们称之为背景常识推理( CCI ) 。 我们查看 GLUCOSE ( Mostafazadeh et al. 2020) 的数据集和任务, 以预测故事句子之间的隐含共通推论。 由于 GLUCOSE 任务同时生成句子并预测 CCI 关系, 结果中存在混杂。 模型是真正测量 CCI, 还是它能够生成包含结果的语法文本? 在本文中, 我们介绍在选择句首部分( \ textsc{ CIS ⁇ 2}) 中的任务背景常识推理( ), 简化了任务, 避免通过完全删除语言生成来混杂。 我们的发现强调, 未来工作必须把语言与预期的 NLP 任务区分开来。