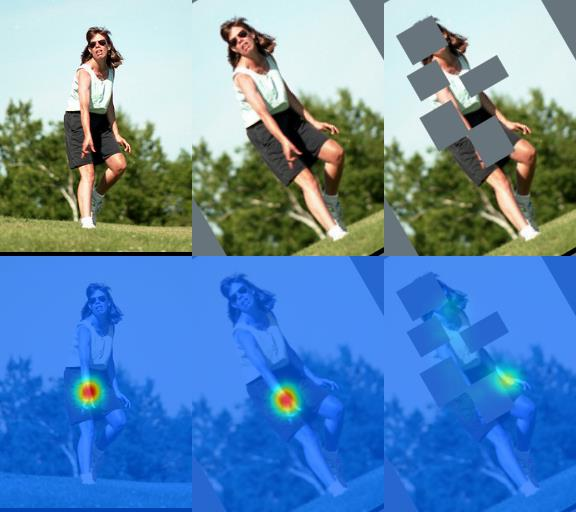
Semi-supervised learning aims to boost the accuracy of a model by exploring unlabeled images. The state-of-the-art methods are consistency-based which learn about unlabeled images by encouraging the model to give consistent predictions for images under different augmentations. However, when applied to pose estimation, the methods degenerate and predict every pixel in unlabeled images as background. This is because contradictory predictions are gradually pushed to the background class due to highly imbalanced class distribution. But this is not an issue in supervised learning because it has accurate labels. This inspires us to stabilize the training by obtaining reliable pseudo labels. Specifically, we learn two networks to mutually teach each other. In particular, for each image, we compose an easy-hard pair by applying different augmentations and feed them to both networks. The more reliable predictions on easy images in each network are used to teach the other network to learn about the corresponding hard images. The approach successfully avoids degeneration and achieves promising results on public datasets. The source code and pretrained models have been released at https://github.com/xierc/Semi_Human_Pose.
翻译:半监督的学习旨在通过探索未贴标签的图像来提高模型的准确性。 最先进的方法基于一致性, 学习未贴标签的图像, 鼓励模型对不同增强度下的图像作出一致的预测。 但是, 当应用来做出估计时, 方法会退化, 并预测未贴标签的图像中的每一像素作为背景。 这是因为由于等级分布高度不平衡, 矛盾的预测会逐渐推到背景类中。 但是这不是监督学习中的一个问题, 因为它有准确的标签。 这激励我们通过获取可靠的假标签来稳定培训。 具体地说, 我们学习了两个网络, 互相教对方。 特别是, 我们通过应用不同的增强度, 将两者配对简单化。 每个网络简单图像上的更可靠的预测被用来教给其他网络学习相应的硬图像。 这种方法成功地避免了退化, 并在公共数据集上取得了令人乐观的结果 。 源代码和预先培训的模型已经在 https://github.com/xierc/Semia_HHR_Pose_Pose 上发布 。