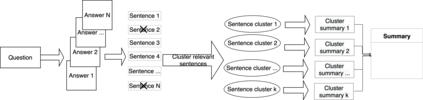
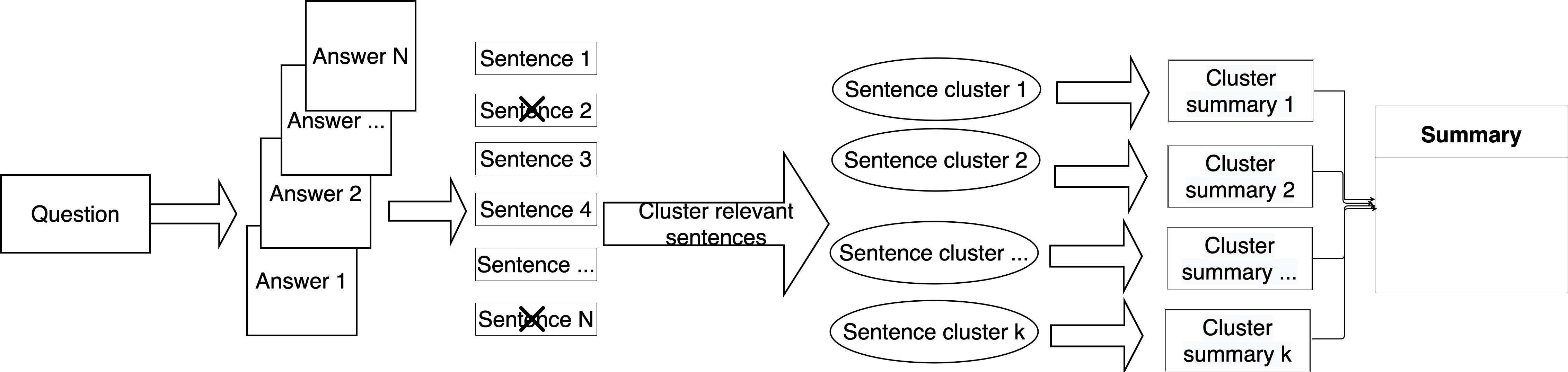
Community Question Answering (CQA) fora such as Stack Overflow and Yahoo! Answers contain a rich resource of answers to a wide range of community-based questions. Each question thread can receive a large number of answers with different perspectives. One goal of answer summarization is to produce a summary that reflects the range of answer perspectives. A major obstacle for this task is the absence of a dataset to provide supervision for producing such summaries. Recent works propose heuristics to create such data, but these are often noisy and do not cover all answer perspectives present. This work introduces a novel dataset of 4,631 CQA threads for answer summarization curated by professional linguists. Our pipeline gathers annotations for all subtasks of answer summarization, including relevant answer sentence selection, grouping these sentences based on perspectives, summarizing each perspective, and producing an overall summary. We analyze and benchmark state-of-the-art models on these subtasks and introduce a novel unsupervised approach for multi-perspective data augmentation that boosts summarization performance according to automatic evaluation. Finally, we propose reinforcement learning rewards to improve factual consistency and answer coverage and analyze areas for improvement.
翻译:社区问题解答( CQA) 论坛, 如 Stack Overflow 和 Yahoo 。 答案包含对一系列社区问题回答的丰富资源。 每条问题线索都可以从不同角度获得大量解答。 答案总和的一个目标是产生一个反映回答观点的概要。 这项任务的一个主要障碍是缺少一个数据集来监督这种摘要的编制工作。 最近的工作提出了创建这些数据的超常性, 但这些数据往往很吵闹, 并不包含所有答案的视角 。 这项工作引入了一套4, 631 CQA 线索的新数据集, 供专业语言用户校准答案总和。 我们的管道收集了所有回答总和子任务的说明, 包括相关的回答句选择, 根据视角将这些句子分组, 总结每个视角, 并产生一个总体摘要。 我们对这些子任务中的最新模型进行分析和基准, 并引入了一种新的、 未经校正的多面化数据增强方法, 即根据自动评估进行推算的推算和推算, 我们建议加强评级, 改进真实性回答。