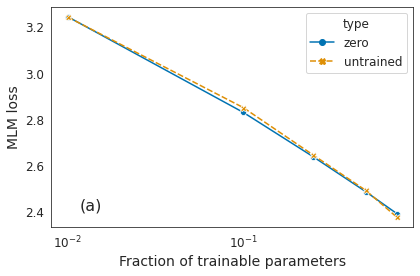
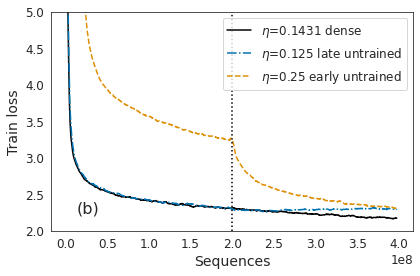
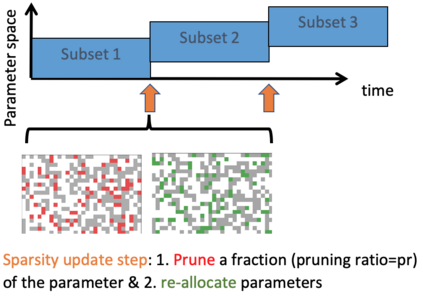
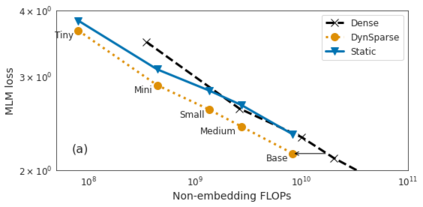
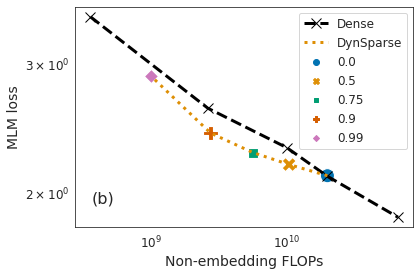
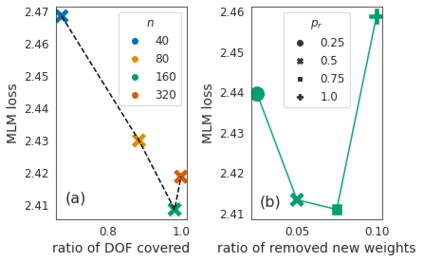
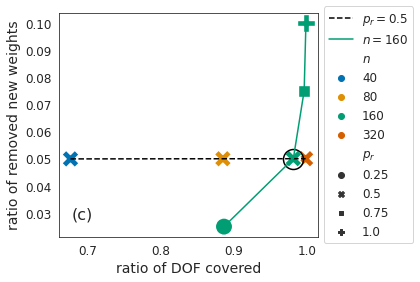
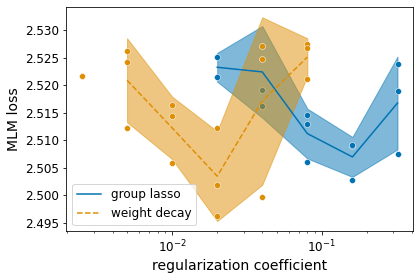
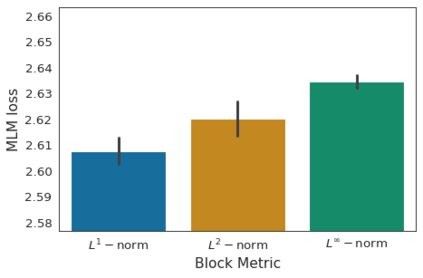
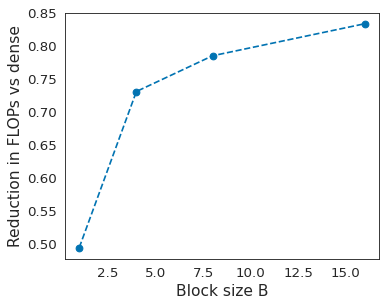
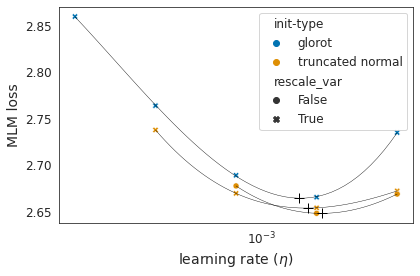
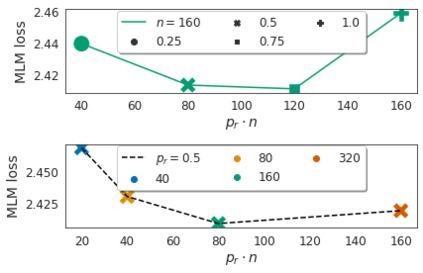
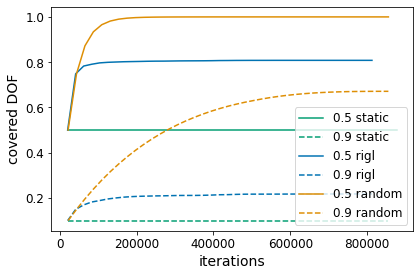
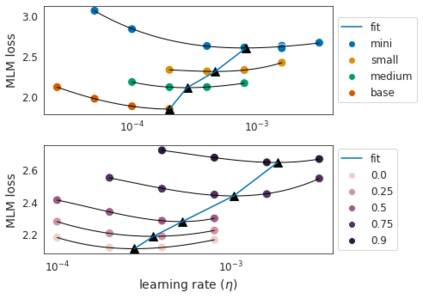
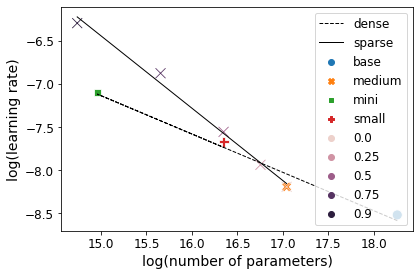
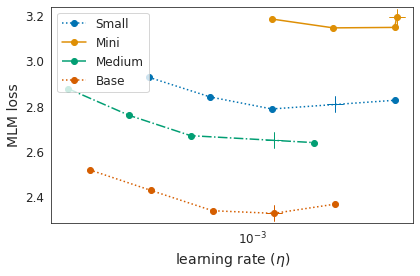
Identifying algorithms for computational efficient unsupervised training of large language models is an important and active area of research. In this work, we develop and study a straightforward, dynamic always-sparse pre-training approach for BERT language modeling task, which leverages periodic compression steps based on magnitude pruning followed by random parameter re-allocation. This approach enables us to achieve Pareto improvements in terms of the number of floating-point operations (FLOPs) over statically sparse and dense models across a broad spectrum of network sizes. Furthermore, we demonstrate that training remains FLOP-efficient when using coarse-grained block sparsity, making it particularly promising for efficient execution on modern hardware accelerators.
翻译:在这项工作中,我们制定和研究一种直接的、动态的、总是粗糙的训练前方法,用于BERT语言建模任务,该方法利用基于规模裁剪的定期压缩步骤,然后随机调整参数重新定位。 这种方法使我们能够在移动点操作数量方面实现Pareto的改进,而浮点操作(FLOPs)比固定的分散和密集的模型在广泛的网络规模上进行。此外,我们还表明,在使用粗糙的块状聚居时,培训仍然有效,这特别有利于在现代硬件加速器上高效地执行。