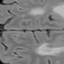
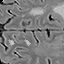
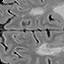
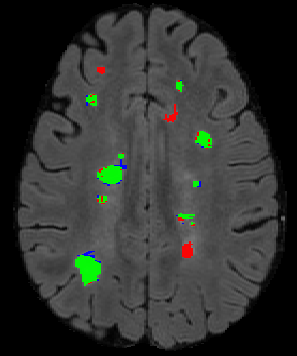
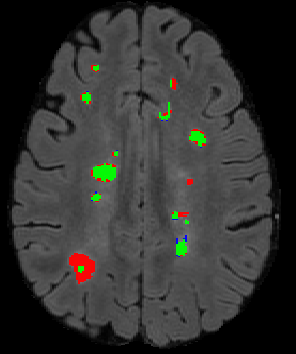
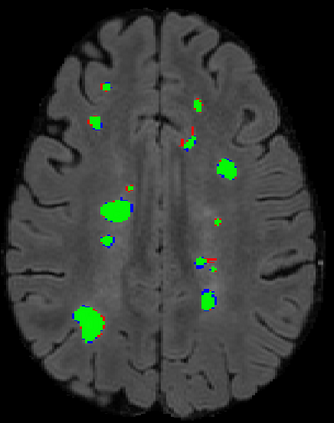
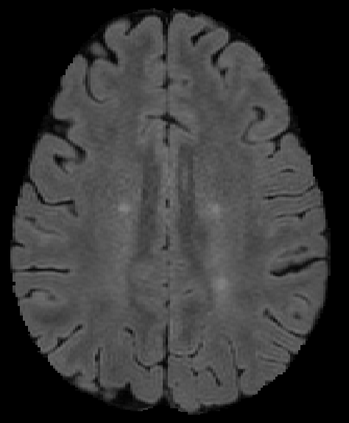
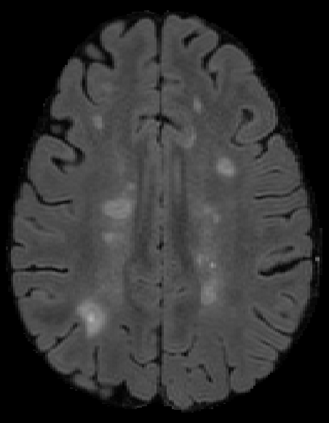
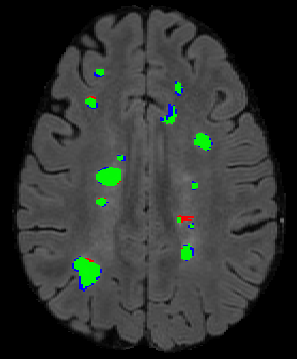
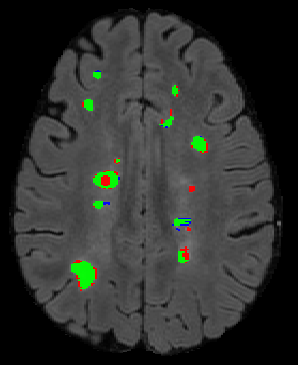
The detection of new multiple sclerosis (MS) lesions is an important marker of the evolution of the disease. The applicability of learning-based methods could automate this task efficiently. However, the lack of annotated longitudinal data with new-appearing lesions is a limiting factor for the training of robust and generalizing models. In this work, we describe a deep-learning-based pipeline addressing the challenging task of detecting and segmenting new MS lesions. First, we propose to use transfer-learning from a model trained on a segmentation task using single time-points. Therefore, we exploit knowledge from an easier task and for which more annotated datasets are available. Second, we propose a data synthesis strategy to generate realistic longitudinal time-points with new lesions using single time-point scans. In this way, we pretrain our detection model on large synthetic annotated datasets. Finally, we use a data-augmentation technique designed to simulate data diversity in MRI. By doing that, we increase the size of the available small annotated longitudinal datasets. Our ablation study showed that each contribution lead to an enhancement of the segmentation accuracy. Using the proposed pipeline, we obtained the best score for the segmentation and the detection of new MS lesions in the MSSEG2 MICCAI challenge.
翻译:检测新的多发性硬化病(MS)损伤是该疾病演变的重要标志。学习方法的应用可以有效地使这项任务自动化。然而,缺乏附加注释的纵向数据与新发现的损伤是培训稳健和概括模型的一个限制因素。在这项工作中,我们描述了一个基于深层次学习的管道,处理发现和分解新的MS损伤这一具有挑战性的任务。首先,我们建议使用利用单一时间点进行分解任务培训的模型的转移-学习。因此,我们利用从较容易的任务中获取的知识,并因此有更多附加注释的数据集。第二,我们提出数据合成战略,利用单一时间点扫描,产生现实的纵向时间点,产生新的损伤。这样,我们将我们的检测模型预先放在大型合成附加注释的数据集上。最后,我们使用一种数据强化技术来模拟MSSS的数据多样性。我们通过这样做,增加了现有的小型经注释的纵向数据集的大小。我们进行的一项数据综合分析研究显示,我们利用每分级分级的每分级分级分级,我们获得了MISA的分级。