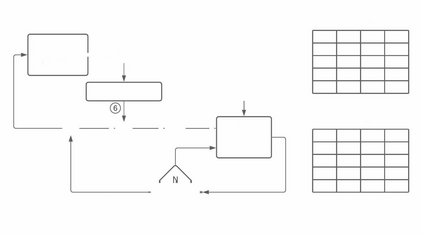
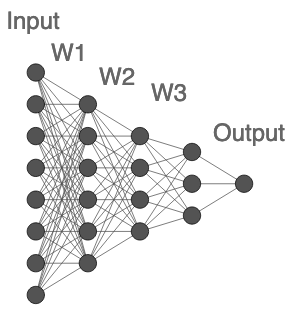
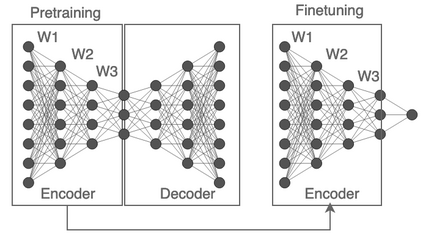
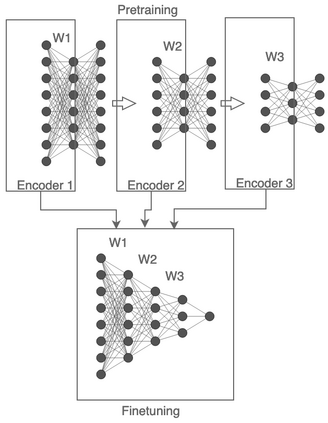
Fully connected deep neural networks (DNN) often include redundant weights leading to overfitting and high memory requirements. Additionally, the performance of DNN is often challenged by traditional machine learning models in tabular data classification. In this paper, we propose periodical perturbations (prune and regrow) of DNN weights, especially at the self-supervised pre-training stage of deep autoencoders. The proposed weight perturbation strategy outperforms dropout learning in four out of six tabular data sets in downstream classification tasks. The L1 or L2 regularization of weights at the same pretraining stage results in inferior classification performance compared to dropout or our weight perturbation routine. Unlike dropout learning, the proposed weight perturbation routine additionally achieves 15% to 40% sparsity across six tabular data sets for the compression of deep pretrained models. Our experiments reveal that a pretrained deep autoencoder with weight perturbation or dropout can outperform traditional machine learning in tabular data classification when fully connected DNN fails miserably. However, traditional machine learning models appear superior to any deep models when a tabular data set contains uncorrelated variables. Therefore, the success of deep models can be attributed to the inevitable presence of correlated variables in real-world data sets.
翻译:完全连通的深神经网络(DNN)通常包括导致超装和高记忆要求的冗余重量。此外,DNN的表现经常受到表格数据分类中传统机器学习模式的挑战。在本文中,我们提议对DNN重量进行定期扰动(脉冲和再增长),特别是在深自监督的深自动进化器培训前阶段。拟议的重量扰动战略在下游分类任务的6个表格数据集中的4个中优于辍学学习。同一培训前阶段的 L1 或 L2 重量正规化导致与辍学或我们体重渗透常规相比,分类性表现较差。与辍学学习不同,拟议的重量周期性额外在6个表格数据集中达到15%至40%的悬浮度,用于压缩深层预先训练模型。我们的实验显示,在完全连接 DNNN 或L2 的数据分类中,有误差时,在表层数据分类中,对传统的机器学习模式看来优于任何深度模型,因为表层数据具有不可避免的变化的变量。因此,表层数据中的成功变量可归为真实的。