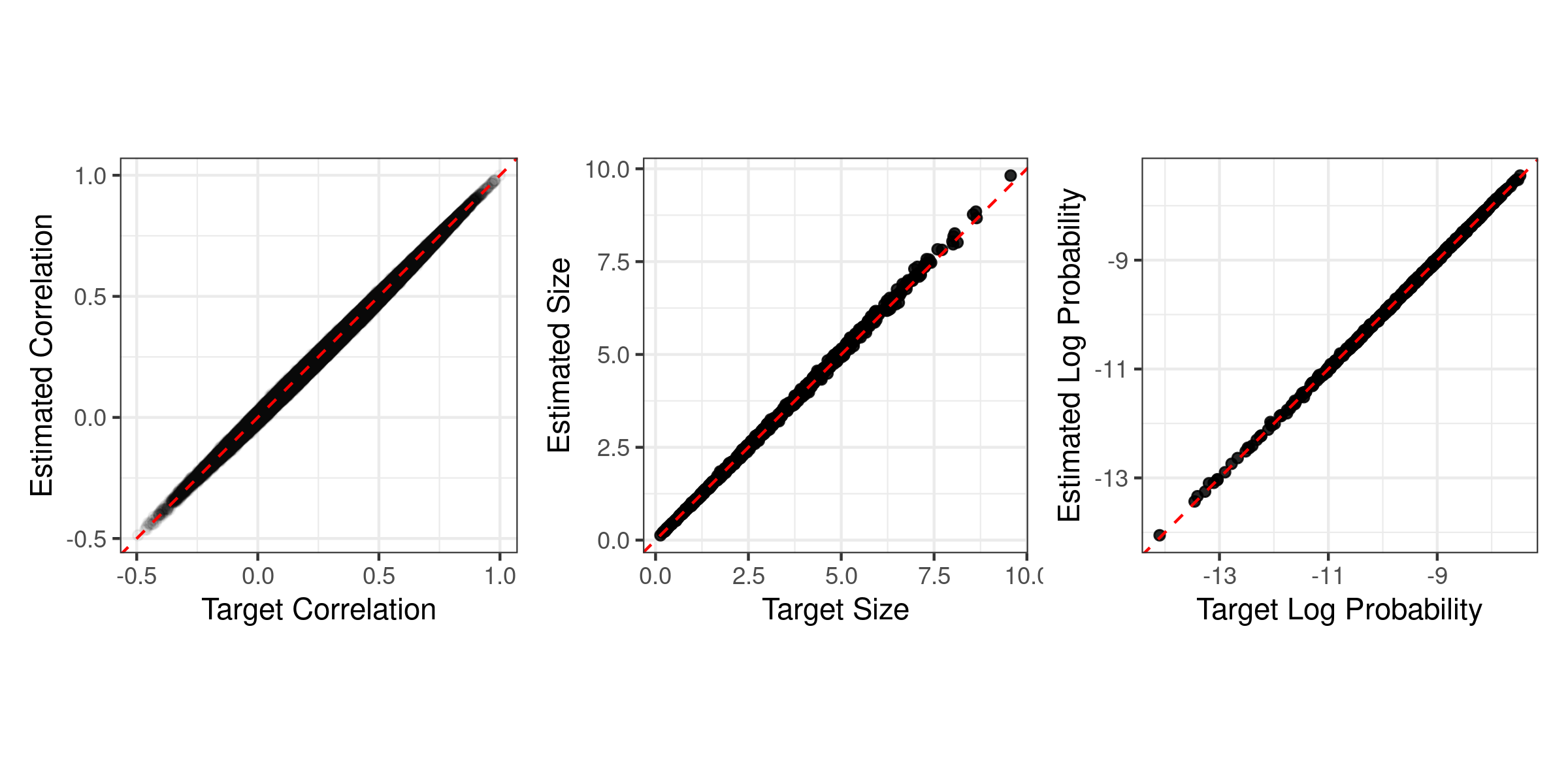
It is critical to accurately simulate data when employing Monte Carlo techniques and evaluating statistical methodology. Measurements are often correlated and high dimensional in this era of big data, such as data obtained in high-throughput biomedical experiments. Due to the computational complexity and a lack of user-friendly software available to simulate these massive multivariate constructions, researchers resort to simulation designs that posit independence or perform arbitrary data transformations. To close this gap, we developed the Bigsimr Julia package with R and Python interfaces. This paper focuses on the R interface. These packages empower high-dimensional random vector simulation with arbitrary marginal distributions and dependency via a Pearson, Spearman, or Kendall correlation matrix. bigsimr contains high-performance features, including multi-core and graphical-processing-unit-accelerated algorithms to estimate correlation and compute the nearest correlation matrix. Monte Carlo studies quantify the accuracy and scalability of our approach, up to $d=10,000$. We describe example workflows and apply to a high-dimensional data set -- RNA-sequencing data obtained from breast cancer tumor samples.
翻译:在使用蒙特卡洛技术和评估统计方法时,准确模拟数据至关重要。在这个大数据时代,计量往往是相关和高维的,例如高通量生物医学实验中获得的数据。由于计算的复杂性和缺乏可用于模拟这些大规模多变量构造的方便用户的软件,研究人员采用假设独立或任意进行数据转换的模拟设计。为了缩小这一差距,我们用R和Python界面开发了Bigsimr Julia软件包。本文侧重于R界面。这些软件包通过Pearson、Spearman或Kendall相关矩阵使高维随机矢量模拟具有任意边际分布和依赖性。大型模拟软件含有高性性能特征,包括多极和图形处理单位加速算法,以估计相关性和计算最近的相关矩阵。蒙特卡洛研究量化了我们方法的准确性和可扩展性,最高达1万美元。我们描述了各种工作流程,并适用于一套高度数据集 -- 从乳腺癌肿瘤样本中获得的RNA序列数据。