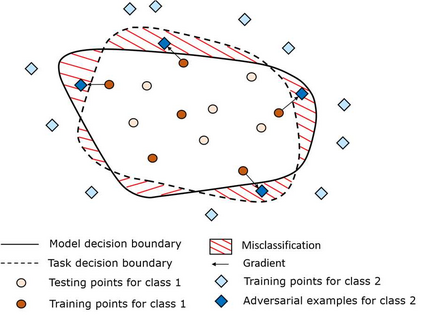
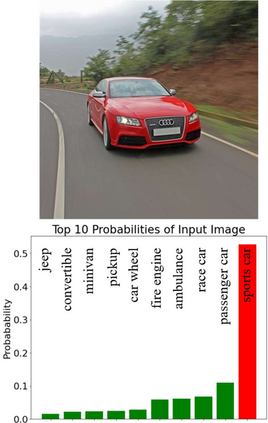
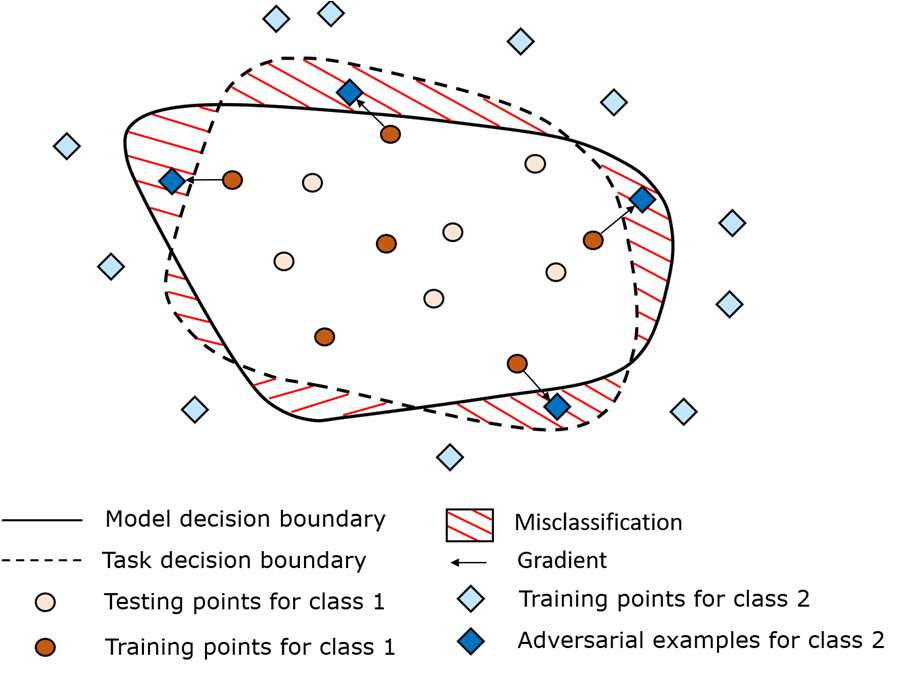
Developing consistently well performing visual recognition applications based on convolutional neural networks, e.g. for autonomous driving, is very challenging. One of the obstacles during the development is the opaqueness of their cognitive behaviour. A considerable amount of literature has been published which describes irrational behaviour of trained CNNs showcasing gaps in their cognition. In this paper, a methodology is presented that creates worstcase images using image augmentation techniques. If the CNN's cognitive performance on such images is weak while the augmentation techniques are supposedly harmless, a potential gap in the cognition has been found. The presented worst-case image generator is using adversarial search approaches to efficiently identify the most challenging image. This is evaluated with the well-known AlexNet CNN using images depicting a typical driving scenario.
翻译:发展过程中的一个障碍是其认知行为不透明。已经出版了大量文献,描述了受过训练的有线电视新闻网的不理性行为,显示其认知能力的差距。本文介绍了一种方法,利用图像增强技术制作最坏的图像。如果有线电视新闻网在这些图像上的认知性表现较弱,而增强技术据说是无害的,那么在认知能力方面可能存在差距。最坏的图像生成器正在使用对抗性搜索方法,以有效识别最具挑战性的形象。这与著名的亚历克斯网有线电视新闻网使用描述典型驱动情景的图像进行了评估。