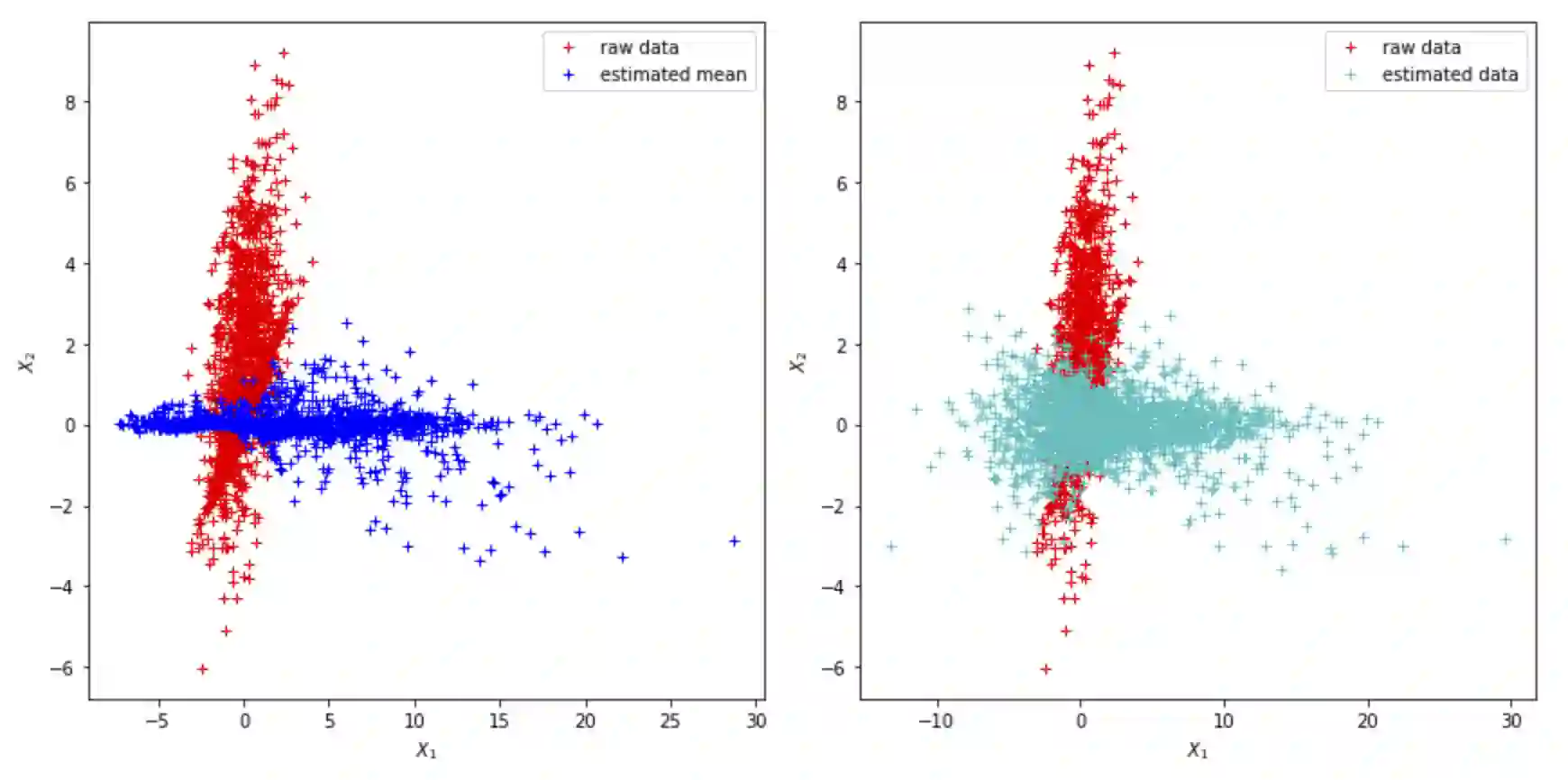
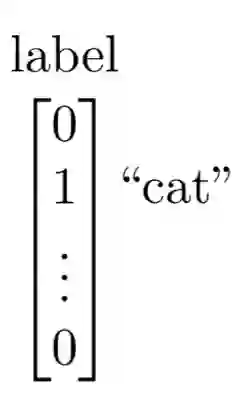
Due to spurious correlations, machine learning systems often fail to generalize to environments whose distributions differ from the ones used at training time. Prior work addressing this, either explicitly or implicitly, attempted to find a data representation that has an invariant relationship with the target. This is done by leveraging a diverse set of training environments to reduce the effect of spurious features and build an invariant predictor. However, these methods have generalization guarantees only when both data representation and classifiers come from a linear model class. We propose invariant Causal Representation Learning (iCaRL), an approach that enables out-of-distribution (OOD) generalization in the nonlinear setting (i.e., nonlinear representations and nonlinear classifiers). It builds upon a practical and general assumption: the prior over the data representation (i.e., a set of latent variables encoding the data) given the target and the environment belongs to general exponential family distributions. Based on this, we show that it is possible to identify the data representation up to simple transformations. We also prove that all direct causes of the target can be fully discovered, which further enables us to obtain generalization guarantees in the nonlinear setting. Extensive experiments on both synthetic and real-world datasets show that our approach outperforms a variety of baseline methods. Finally, in the discussion, we further explore the aforementioned assumption and propose a more general hypothesis, called the Agnostic Hypothesis: there exist a set of hidden causal factors affecting both inputs and outcomes. The Agnostic Hypothesis can provide a unifying view of machine learning. More importantly, it can inspire a new direction to explore a general theory for identifying hidden causal factors, which is key to enabling the OOD generalization guarantees.
翻译:由于虚假的关联,机器学习系统往往无法概括到分布不同于培训时所用分布的环境。 之前的工作是明确或隐含地试图找到一个与目标有异同关系的数据表示方式。 这是通过利用一系列不同的培训环境来减少虚假特征的影响并建立一个不固定的预测器。 然而, 这些方法只有在数据表达方式和分类方法都来自线性模型类时才具有概括性保障。 我们提议了一种差异性 Causal 表示方式( iCaRL), 这种方法可以让非线性环境( 即非线性表示和非线性分类) 的分布性( OOOD) 概括化( OOD) 。 之前的工作试图找到一个与目标有异异的关系的数据表示方式。 它基于一个实际的假设: 之前的一组潜在变量将数据表达到数据分布于一般指数式的家庭分布。 在此基础上, 我们表明, 存在一个数据表示到简单转换的数据表示到简单的转换。 我们还证明, 所有目标的直接原因都可以在非线性输入一个秘密的理论, 使得我们能够更精确地展示一个真正的实验方法。