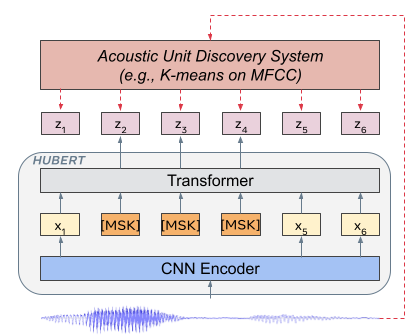
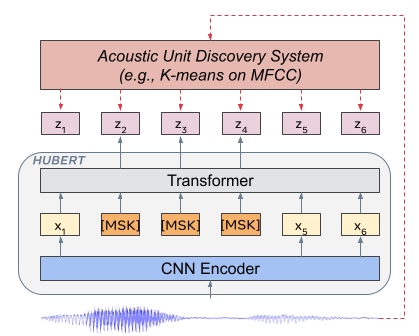
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
翻译:语言代表学习的自我监督方法面临三个独特的问题:(1) 每个输入语句中都有多个声音单位,(2) 培训前阶段没有输入声音单位的词汇,(3) 声音单位的长度各异,没有明确的分解。 要解决这三个问题,我们建议采用隐藏单位BERT(HuBERT) 的自我监督语言代表学习方法,该方法使用离线分组制步骤,为类似于BERT的预测损失提供一致的目标标签。我们方法的一个关键要素是将预测损失仅仅应用在蒙面区域,这迫使模型学习混合的声学和语言模式,而不是连续输入。 HuBERT主要依靠非监督的组合步骤的一致性,而不是指定分组标签的内在质量。 从100个群组的简单K手段教师开始,并使用两个循环,即HuBERERT模式,或者匹配或改进了在利比斯(960h) 和利比勒斯(60h) 和利比勒-比勒-比勒-调10BH) 和比勒- 10BH- 级(60) 和下级(10Bh) 将基准值调整为10BH- b)。