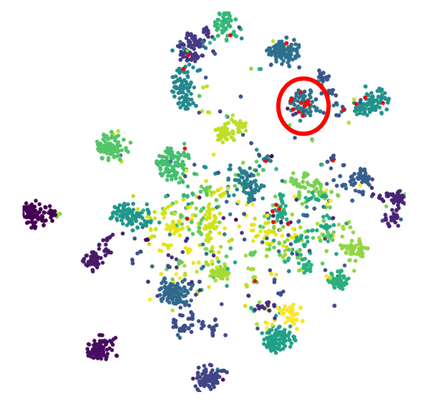
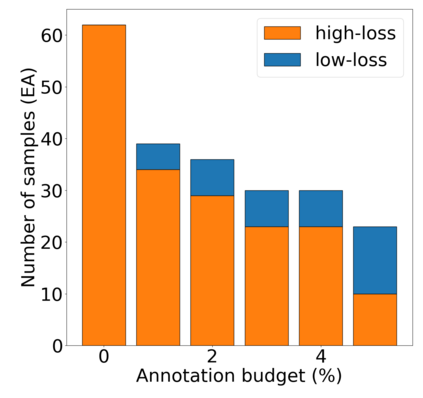
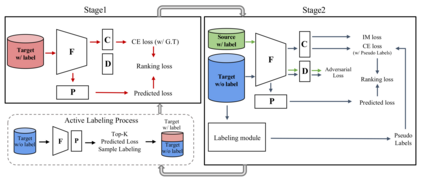
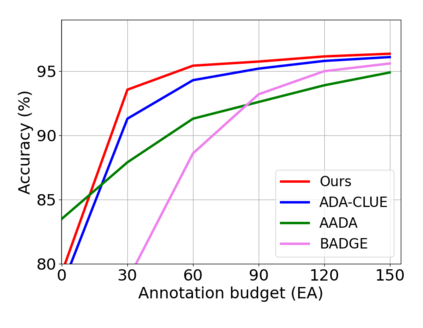
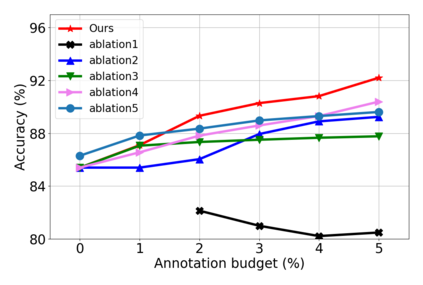
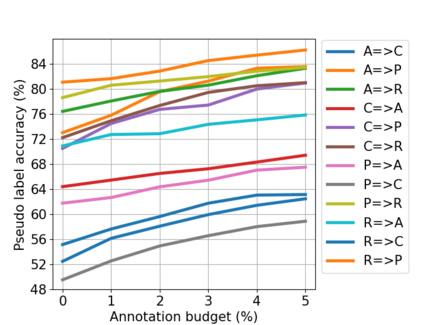
Active domain adaptation (ADA) studies have mainly addressed query selection while following existing domain adaptation strategies. However, we argue that it is critical to consider not only query selection criteria but also domain adaptation strategies designed for ADA scenarios. This paper introduces sequential learning considering both domain type (source/target) or labelness (labeled/unlabeled). We first train our model only on labeled target samples obtained by loss-based query selection. When loss-based query selection is applied under domain shift, unuseful high-loss samples gradually increase, and the labeled-sample diversity becomes low. To solve these, we fully utilize pseudo labels of the unlabeled target domain by leveraging loss prediction. We further encourage pseudo labels to have low self-entropy and diverse class distributions. Our model significantly outperforms previous methods as well as baseline models in various benchmark datasets.
翻译:主动领域适应(ADA)研究主要在遵循现有领域适应战略的同时处理查询选择问题。然而,我们认为,不仅考虑查询选择标准,而且考虑为ADA设想方案设计的域适应战略至关重要。本文介绍了考虑到域类型(源/目标)或标签(标签/未标签)的顺序学习。我们首先对模型进行了培训,仅针对通过基于损失的查询选择获得的标签目标样本。当根据域转移应用基于损失的查询选择时,不有用的高损失样本逐渐增加,而标签型多样性也越来越低。为解决这些问题,我们充分利用未标目标域的假标签,利用损失预测。我们进一步鼓励假标签具有低自湿性和多样性的分类分布。我们的模式大大优于以往的方法以及各种基准数据集中的基线模型。