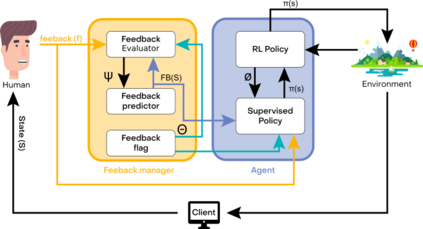
Reinforcement Learning (RL) in various decision-making tasks of machine learning provides effective results with an agent learning from a stand-alone reward function. However, it presents unique challenges with large amounts of environment states and action spaces, as well as in the determination of rewards. This complexity, coming from high dimensionality and continuousness of the environments considered herein, calls for a large number of learning trials to learn about the environment through Reinforcement Learning. Imitation Learning (IL) offers a promising solution for those challenges using a teacher. In IL, the learning process can take advantage of human-sourced assistance and/or control over the agent and environment. A human teacher and an agent learner are considered in this study. The teacher takes part in the agent training towards dealing with the environment, tackling a specific objective, and achieving a predefined goal. Within that paradigm, however, existing IL approaches have the drawback of expecting extensive demonstration information in long-horizon problems. This paper proposes a novel approach combining IL with different types of RL methods, namely state action reward state action (SARSA) and asynchronous advantage actor-critic (A3C) agents, to overcome the problems of both stand-alone systems. It is addressed how to effectively leverage the teacher feedback, be it direct binary or indirect detailed for the agent learner to learn sequential decision-making policies. The results of this study on various OpenAI Gym environments show that this algorithmic method can be incorporated with different combinations, significantly decreases both human endeavor and tedious exploration process.
翻译:在机器学习的各种决策任务中,强化学习(RL)能够提供有效的成果,使代理商能够从独立的奖励功能中学习;然而,它带来了独特的挑战,环境状态和行动空间众多,在确定奖赏方面也存在独特的挑战。这种复杂性来自这里所考虑的环境的高度多元性和连续性,要求大量学习试验,以便通过强化学习来了解环境。模拟学习(IL)为利用教师解决这些挑战提供了一个有希望的解决方案。在IL,学习过程可以利用人为的协助和/或对代理商和环境的控制。本研究报告考虑了一名人类教师和代理商学习空间以及确定奖赏的确定。教师参与代理商培训,以便处理环境问题,处理具体目标,并实现一个预先确定的目标。但是,在这一模式中,现有的IL方法可以从期待在长期问题中提供广泛的演示信息。在IL与不同类型RL方法相结合,即国家行动奖励行动(SA)以及稳定优势的行为者-成本分析(A3C)的学习过程可以有效地克服这种直接的学习方法。