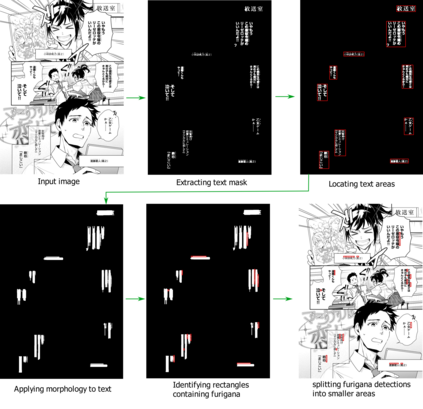
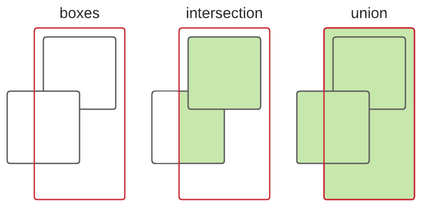
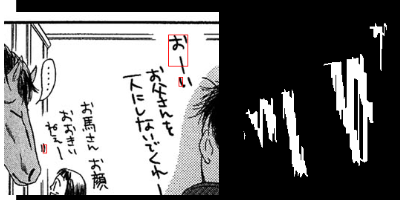
Furigana are pronunciation notes used in Japanese writing. Being able to detect these can help improve optical character recognition (OCR) performance or make more accurate digital copies of Japanese written media by correctly displaying furigana. This project focuses on detecting furigana in Japanese books and comics. While there has been research into the detection of Japanese text in general, there are currently no proposed methods for detecting furigana. We construct a new dataset containing Japanese written media and annotations of furigana. We propose an evaluation metric for such data which is similar to the evaluation protocols used in object detection except that it allows groups of objects to be labeled by one annotation. We propose a method for detection of furigana that is based on mathematical morphology and connected component analysis. We evaluate the detections of the dataset and compare different methods for text extraction. We also evaluate different types of images such as books and comics individually and discuss the challenges of each type of image. The proposed method reaches an F1-score of 76\% on the dataset. The method performs well on regular books, but less so on comics, and books of irregular format. Finally, we show that the proposed method can improve the performance of OCR by 5\% on the manga109 dataset. Source code is available via \texttt{\url{https://github.com/nikolajkb/FuriganaDetection}}
翻译:Furigana 是日本书写中使用的发音笔记。 能够检测这些数据可以帮助提高光学字符识别( OCR) 性能, 或者通过正确显示 furigana 来制作更准确的日本书面媒体数字副本。 该项目侧重于在日本书籍和漫画中检测furigana 。 虽然已经对日本文本的检测进行了总体研究, 但是目前还没有发现furigana 的推荐方法。 我们建造了一个新的数据集, 包含日本书面媒体和furigana 的注释。 我们建议了这类数据的评价标准, 与物体检测中使用的评价协议相似, 但它允许用一个注解标出一组物体。 我们建议了一种基于数学形态学和关联部分分析检测furigana 的方法。 我们评估了对数据集的检测, 并比较了不同的文本提取方法。 我们还单独评估了不同类型的图像, 如书籍和漫画, 并讨论了每种图像的挑战。 提议的方法在数据集上达到了76° 。 方法在常规书籍上运行良好, 但在漫画和O109 rbrbr 版本格式上, 我们最后展示了数据性能通过 Orcrecual 改进。 我们用Oreval 格式改进了数据。