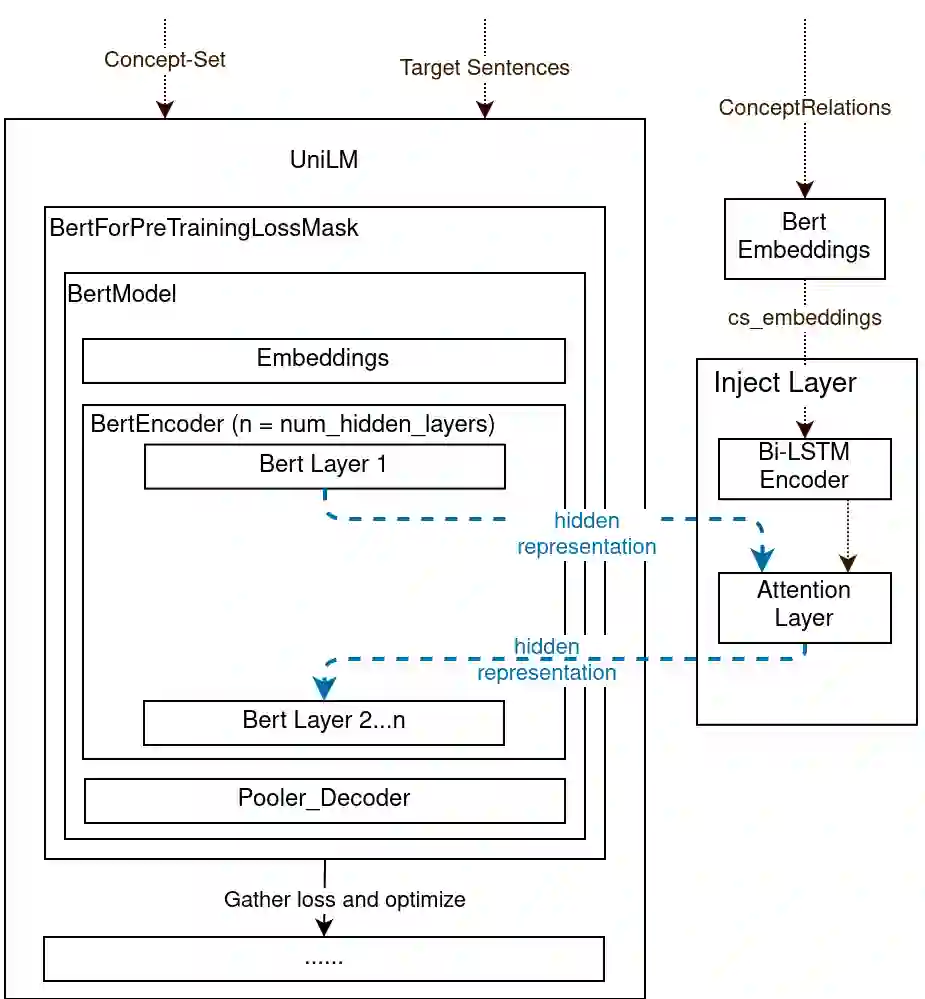
Conditional text generation has been a challenging task that is yet to see human-level performance from state-of-the-art models. In this work, we specifically focus on the Commongen benchmark, wherein the aim is to generate a plausible sentence for a given set of input concepts. Despite advances in other tasks, large pre-trained language models that are fine-tuned on this dataset often produce sentences that are syntactically correct but qualitatively deviate from a human understanding of common sense. Furthermore, generated sequences are unable to fulfill such lexical requirements as matching part-of-speech and full concept coverage. In this paper, we explore how commonsense knowledge graphs can enhance model performance, with respect to commonsense reasoning and lexically-constrained decoding. We propose strategies for enhancing the semantic correctness of the generated text, which we accomplish through: extracting commonsense relations from Conceptnet, injecting these relations into the Unified Language Model (UniLM) through attention mechanisms, and enforcing the aforementioned lexical requirements through output constraints. By performing several ablations, we find that commonsense injection enables the generation of sentences that are more aligned with human understanding, while remaining compliant with lexical requirements.
翻译:有条件的文本生成是一项挑战性的任务,尚未从最先进的模型中看到人文水平的绩效。在这项工作中,我们特别侧重于公元基准,该基准的目的是为一套特定的投入概念创造合理的句子。尽管在其他任务上取得了进展,但对这一数据集进行微调的大型经预先训练的语言模型往往产生在方法上正确但质量上偏离人类对常识的理解的句子。此外,生成的序列无法满足与部分语音和全部概念覆盖相匹配的词汇要求。在本文中,我们探索公元知识图表如何能够在常识推理和有法限制的解码方面提高模型性能。我们提出了加强生成文本的语义正确性的战略,我们通过以下方式完成:从概念网中提取共通关系,通过关注机制将这些关系引入统一语言模型,通过产出限制强制执行上述词汇要求。我们发现,通过执行若干节略,共同思维注入使得生成符合人类理解的版本能够同时符合人类理解的版本的要求。