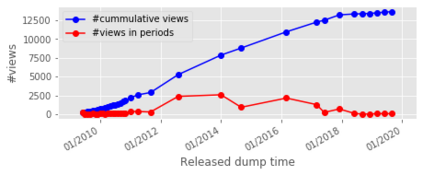
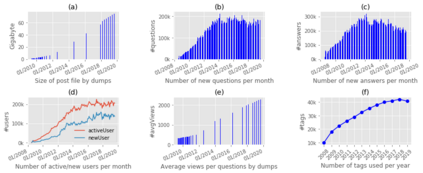
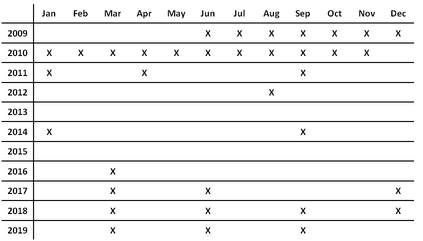
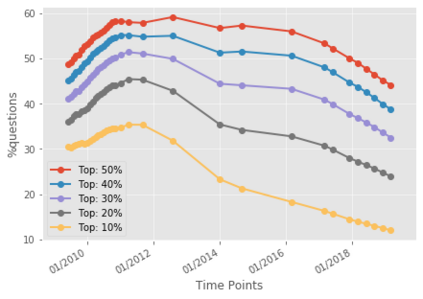
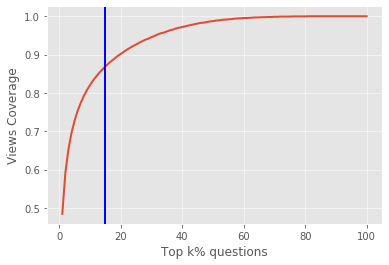
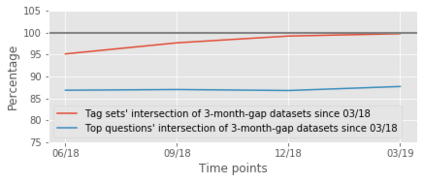
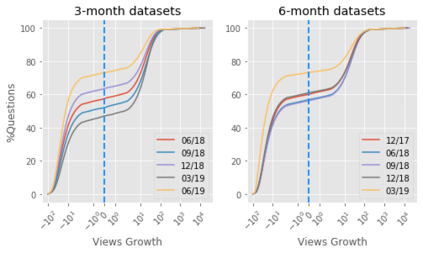
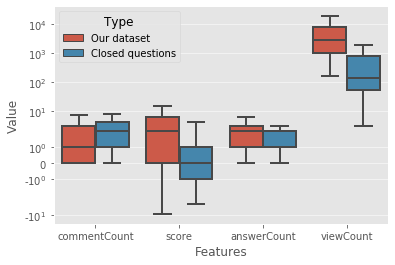
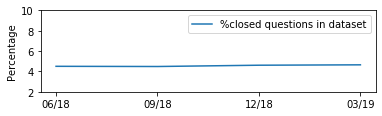
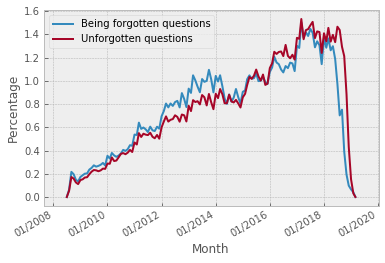
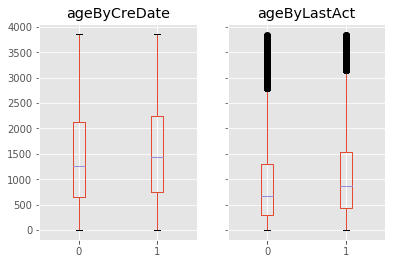
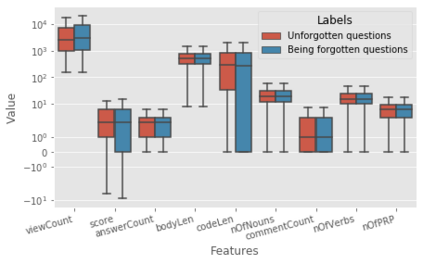
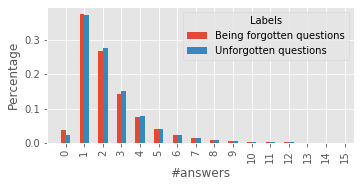
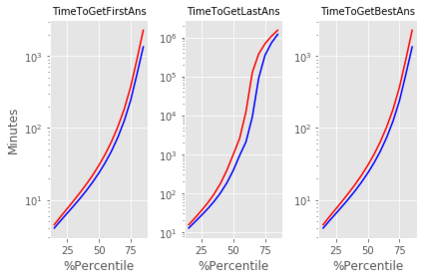
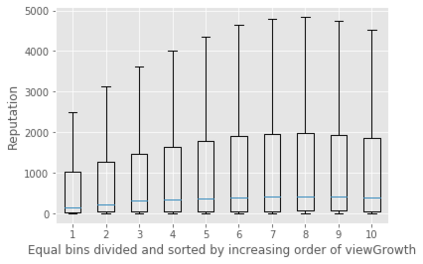
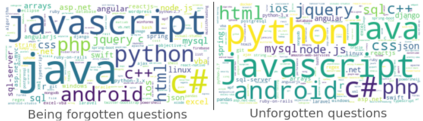
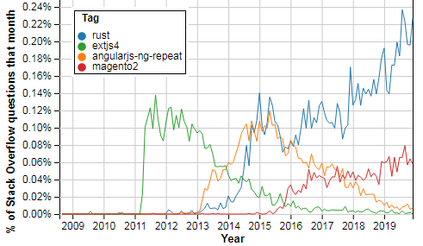
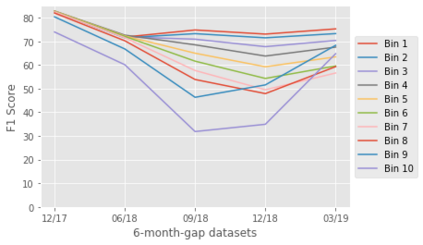
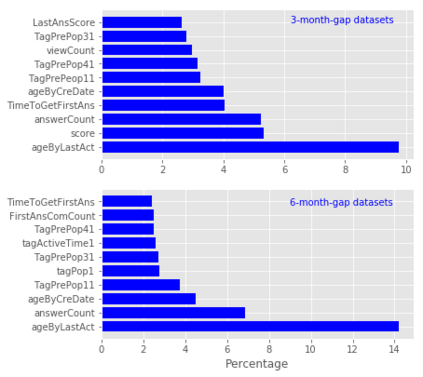
For their attractiveness, comprehensiveness and dynamic coverage of relevant topics, community-based question answering sites such as Stack Overflow heavily rely on the engagement of their communities: Questions on new technologies, technology features as well as technology versions come up and have to be answered as technology evolves (and as community members gather experience with it). At the same time, other questions cease in importance over time, finally becoming irrelevant to users. Beyond filtering low-quality questions, "forgetting" questions, which have become redundant, is an important step for keeping the Stack Overflow content concise and useful. In this work, we study this managed forgetting task for Stack Overflow. Our work is based on data from more than a decade (2008 - 2019) - covering 18.1M questions, that are made publicly available by the site itself. For establishing a deeper understanding, we first analyze and characterize the set of questions about to be forgotten, i.e., questions that get a considerable number of views in the current period but become unattractive in the near future. Subsequently, we examine the capability of a wide range of features in predicting such forgotten questions in different categories. We find some categories in which those questions are more predictable. We also discover that the text-based features are surprisingly not helpful in this prediction task, while the meta information is much more predictive.
翻译:关于新技术、技术特点和技术版本的问题,随着技术的演变(随着社区成员积累经验)而出现,必须回答这些问题。与此同时,其他问题随着时间而停止重要,最终变得与用户无关。除了过滤低质量问题之外,“缓冲”问题已经变得多余,是保持堆叠溢流内容简洁和有用的一个重要步骤。在此工作中,我们研究了这一被遗忘的堆叠溢流任务。我们的工作以十多年(2008-2019年)以来的数据为基础,涵盖18.1M问题,由网站本身公布。为了更深入的理解,我们首先分析和描述一系列有待遗忘的问题,即在当前时期获得大量意见但在近期内变得不吸引人的问题。随后,我们研究了在预测这种被遗忘的问题方面广泛具备的一系列功能的能力。我们发现,在不同的类别中,我们发现一些更具有预测性的问题,而在不同的类别中,我们发现这些是更具有预测性的。我们发现,在不同的类别中,我们发现某些问题也是更具有预测性的。