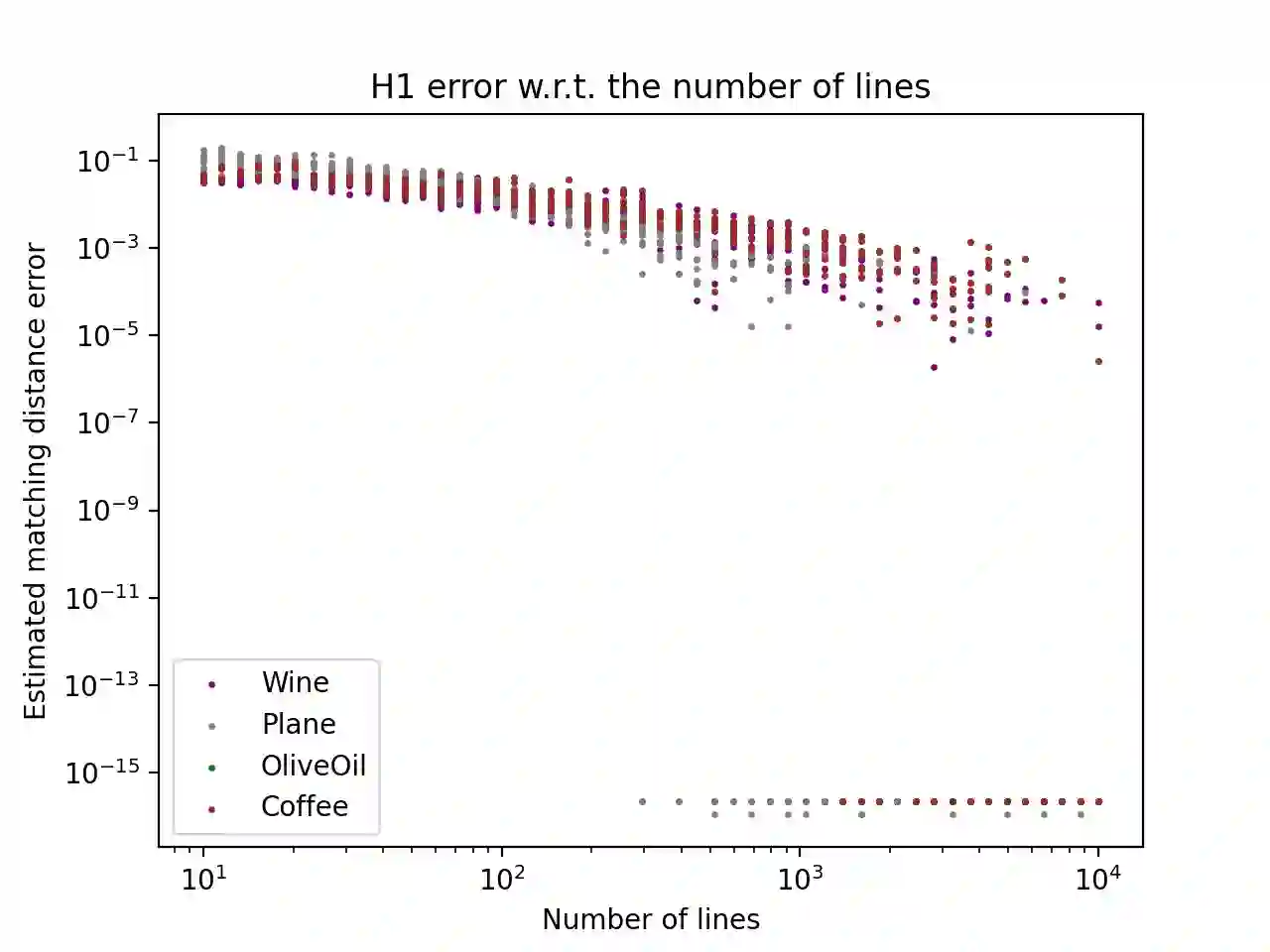
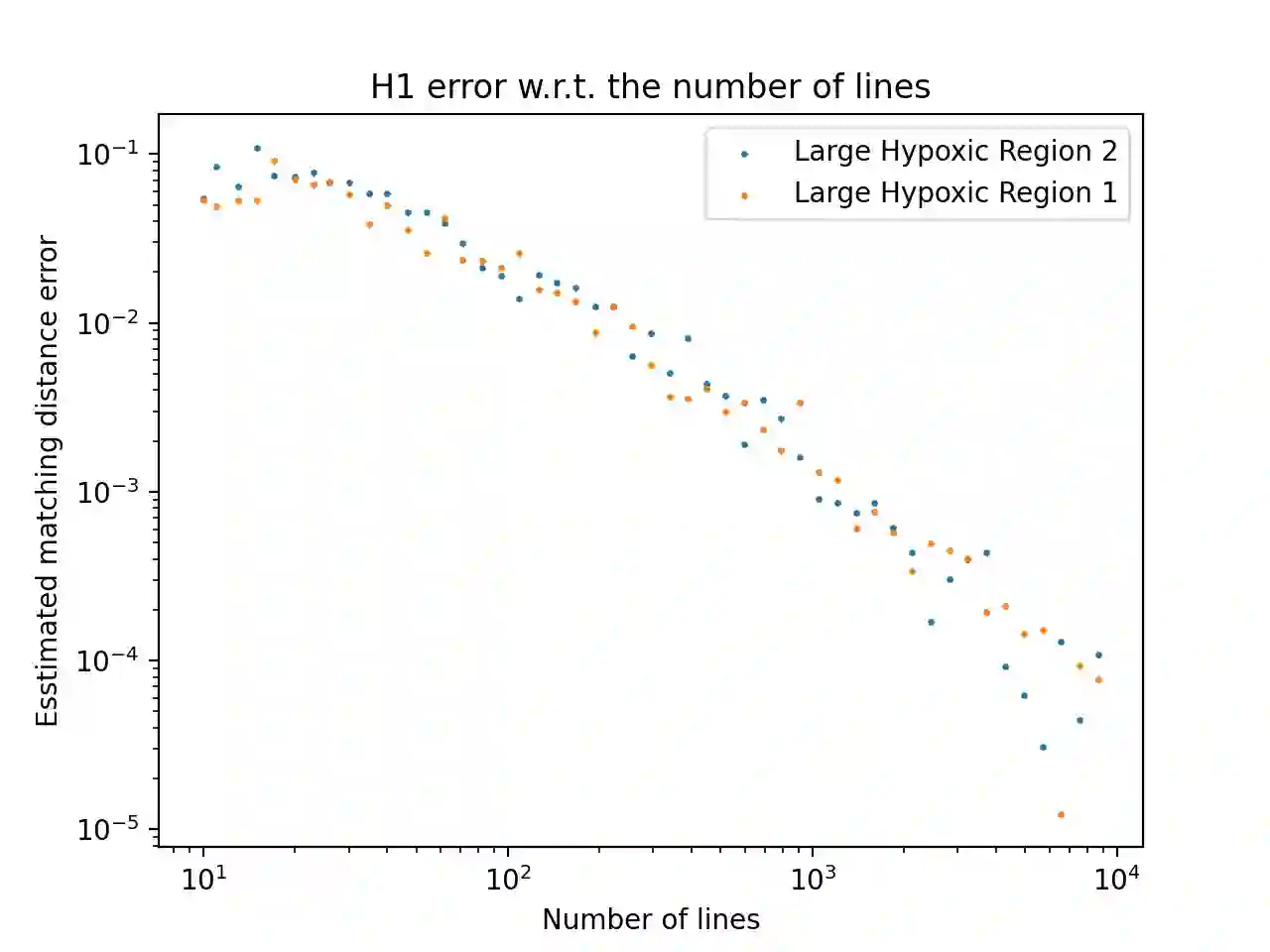
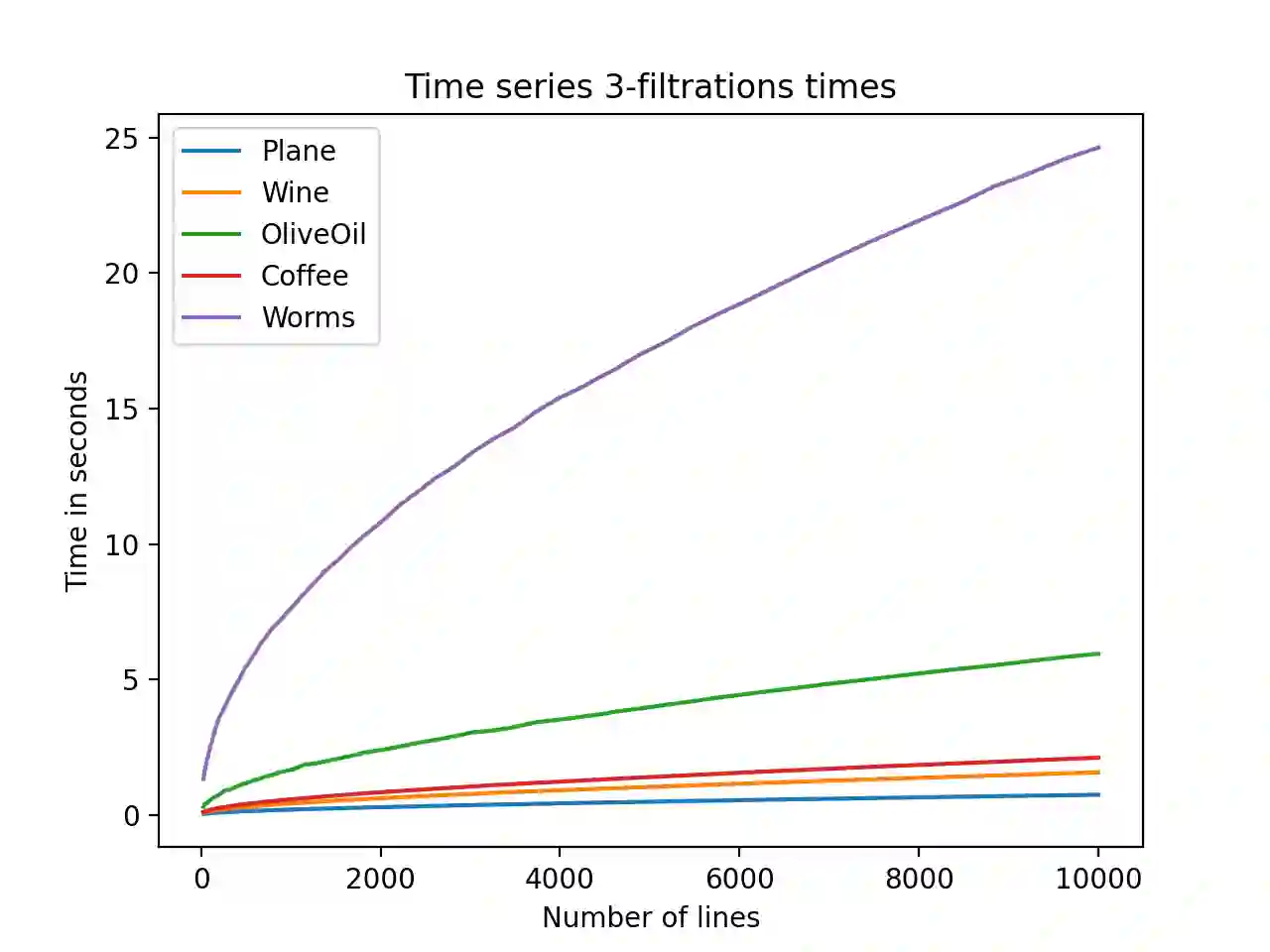
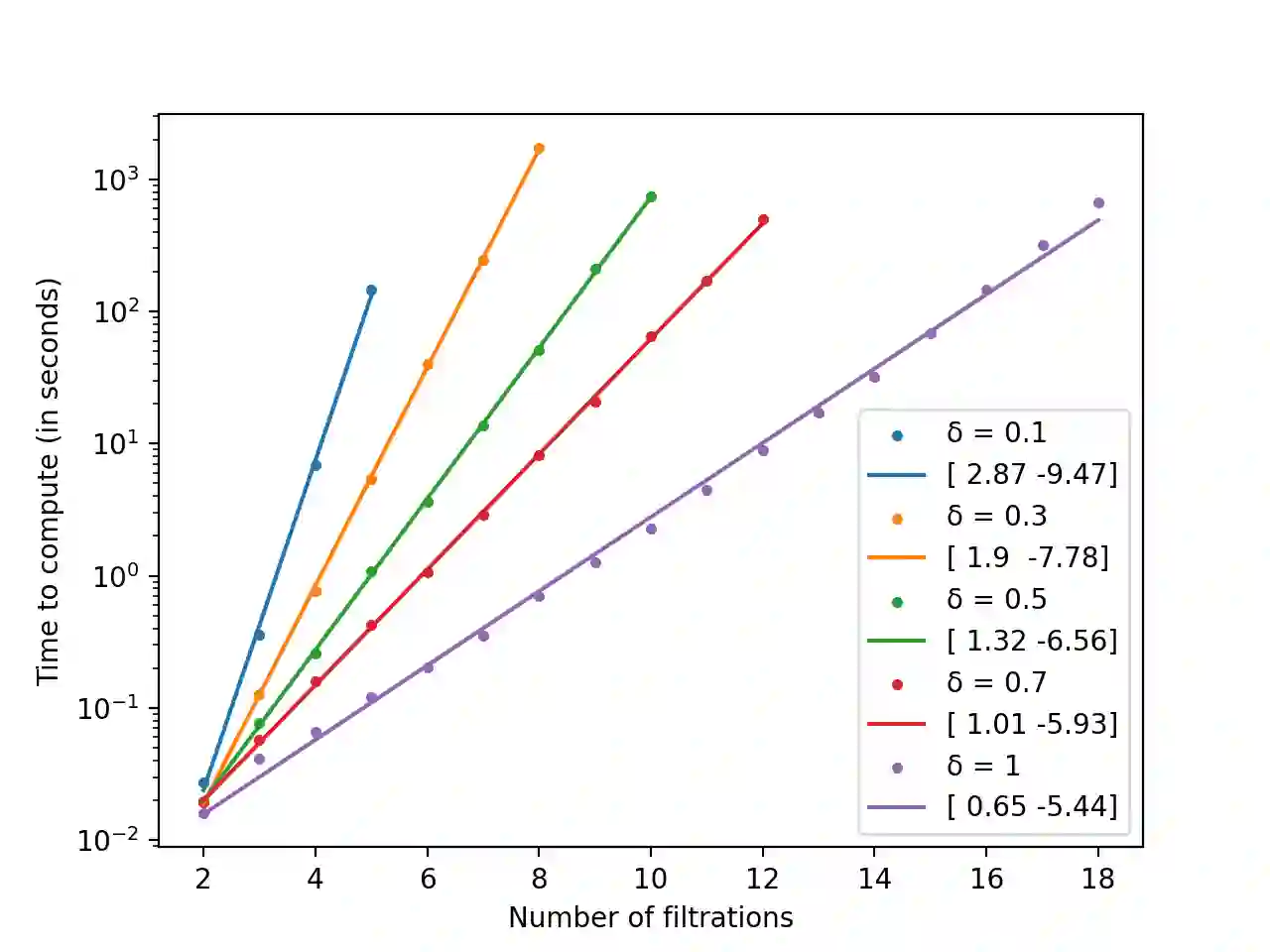
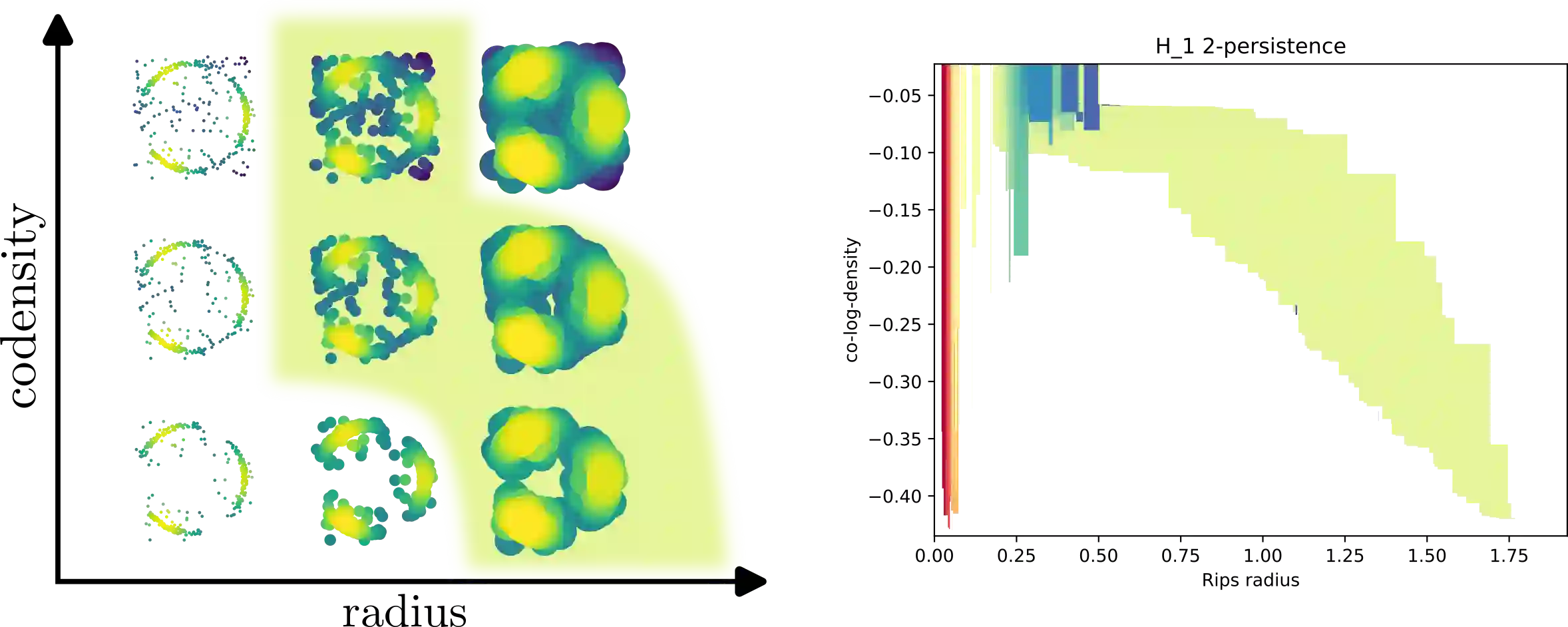Topological Data Analysis is a growing area of data science, which aims at computing and characterizing the geometry and topology of data sets, in order to produce useful descriptors for subsequent statistical and machine learning tasks. Its main computational tool is persistent homology, which amounts to track the topological changes in growing families of subsets of the data set itself, called filtrations, and encode them in an algebraic object, called persistence module. Even though algorithms and theoretical properties of modules are now well-known in the single-parameter case, that is, when there is only one filtration to study, much less is known in the multi-parameter case, where several filtrations are given at once. Though more complicated, the resulting persistence modules are usually richer and encode more information, making them better descriptors for data science. In this article, we present the first approximation scheme, which is based on fibered barcodes and exact matchings, two constructions that stem from the theory of single-parameter persistence, for computing and decomposing general multi-parameter persistence modules. Our algorithm has controlled complexity and running time, and works in arbitrary dimension, i.e., with an arbitrary number of filtrations. Moreover, when restricting to specific classes of multi-parameter persistence modules, namely the ones that can be decomposed into intervals, we establish theoretical results about the approximation error between our estimate and the true module in terms of interleaving distance. Finally, we present empirical evidence validating output quality and speed-up on several data sets.
翻译:暂无翻译