
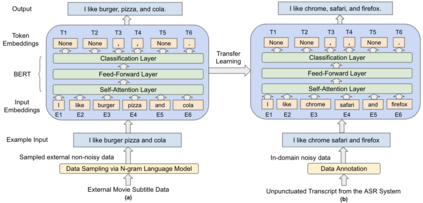
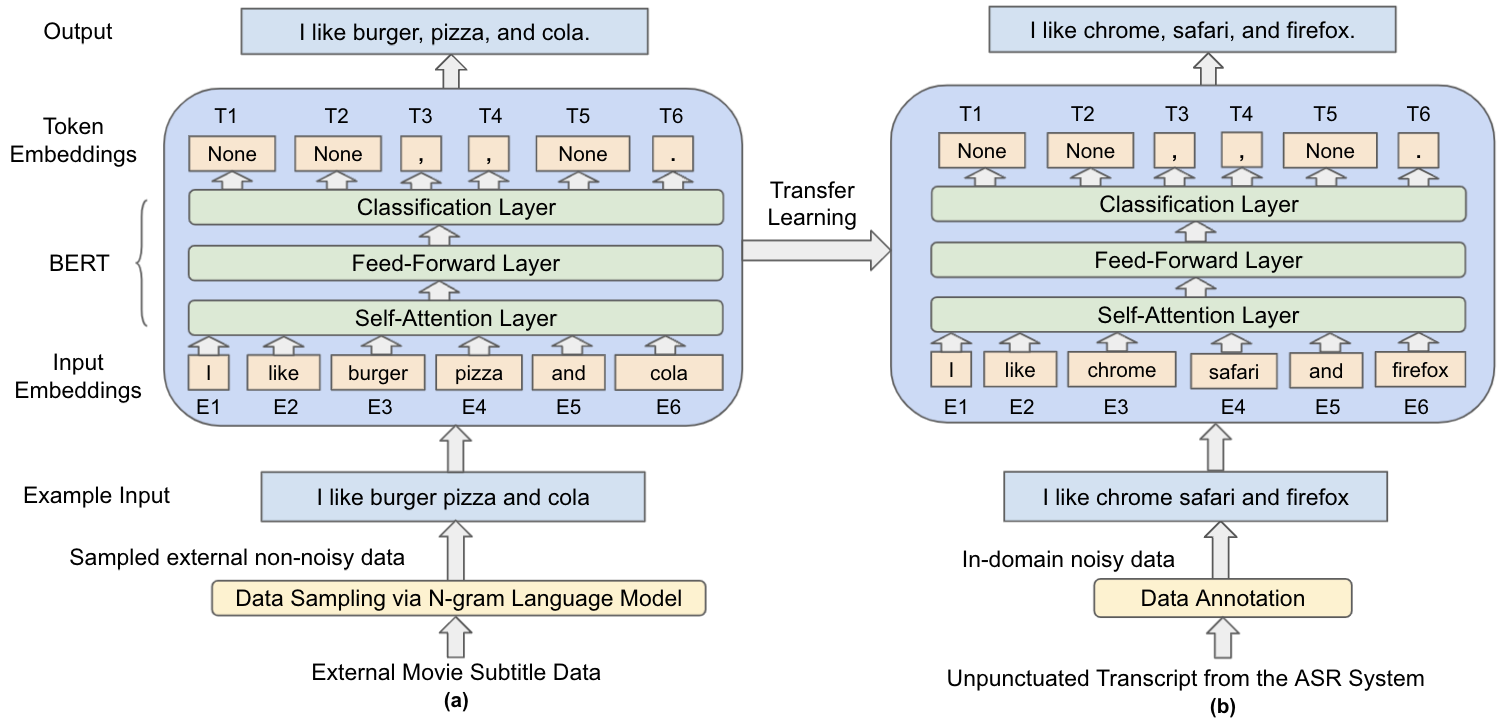
Automatic Speech Recognition (ASR) systems generally do not produce punctuated transcripts. To make transcripts more readable and follow the expected input format for downstream language models, it is necessary to add punctuation marks. In this paper, we tackle the punctuation restoration problem specifically for the noisy text (e.g., phone conversation scenarios). To leverage the available written text datasets, we introduce a data sampling technique based on an n-gram language model to sample more training data that are similar to our in-domain data. Moreover, we propose a two-stage fine-tuning approach that utilizes the sampled external data as well as our in-domain dataset for models based on BERT. Extensive experiments show that the proposed approach outperforms the baseline with an improvement of 1:12% F1 score.
翻译:自动语音识别系统(ASR)通常不会生成标出字稿。为了使记录誊本更易读,并遵循下游语言模型的预期输入格式,有必要添加标注标记。在本文中,我们专门针对噪音文本解决标点恢复问题(例如电话交谈设想方案)。为了利用现有的书面文本数据集,我们采用基于n克语言模型的数据抽样技术,以抽样更多的与我们内部数据类似的培训数据。此外,我们提出一个两阶段的微调方法,利用抽样外部数据以及基于BERT模型的我们内部数据集。广泛的实验表明,拟议的方法比基线高出1:12%的F1分。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem



