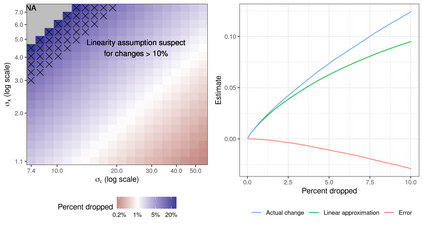
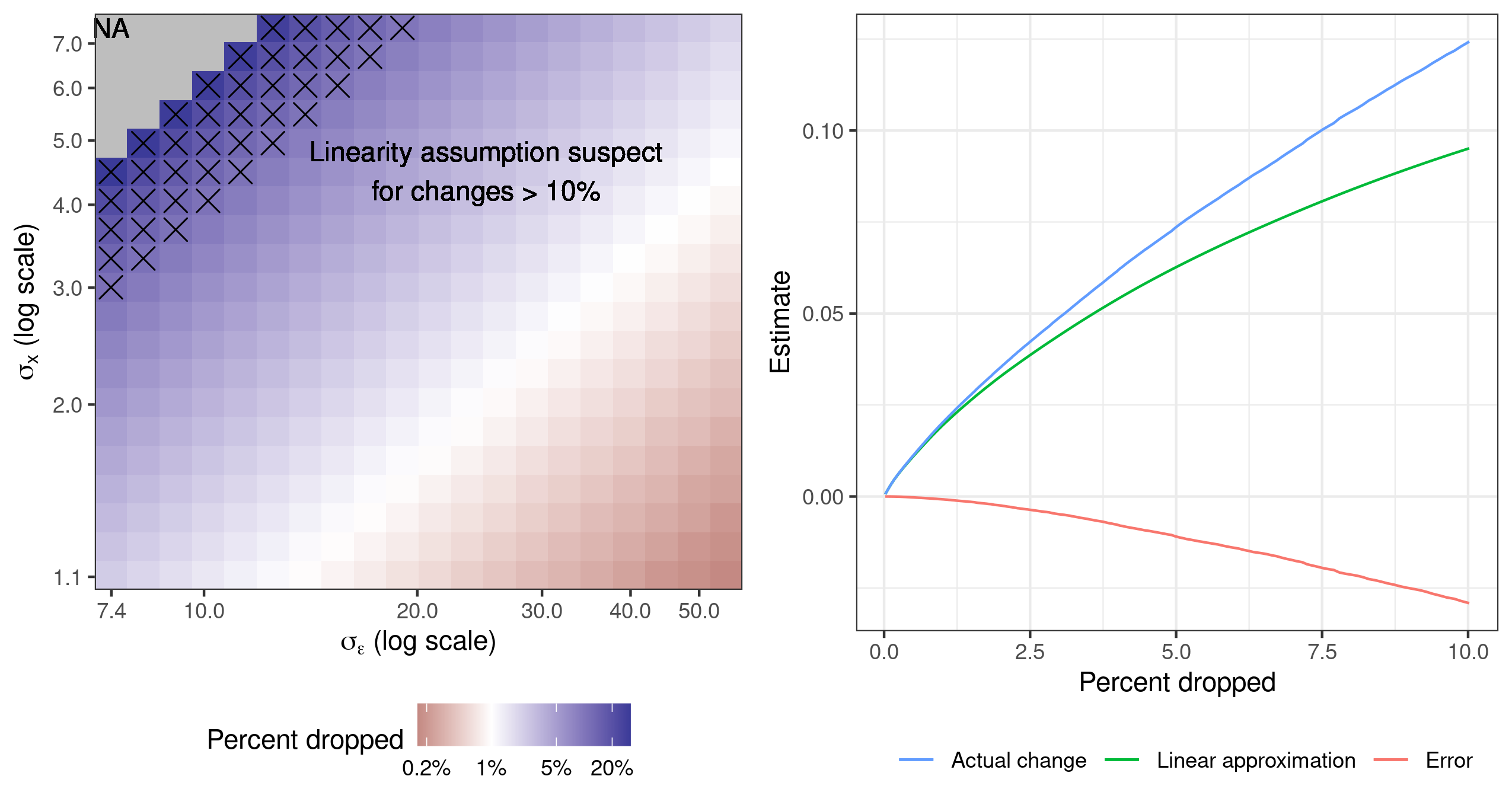
We propose a method to assess the sensitivity of econometric analyses to the removal of a small fraction of the data. Manually checking the influence of all possible small subsets is computationally infeasible, so we provide an approximation to find the most influential subset. Our metric, the "Approximate Maximum Influence Perturbation," is automatically computable for common methods including (but not limited to) OLS, IV, MLE, GMM, and variational Bayes. We provide finite-sample error bounds on approximation performance. At minimal extra cost, we provide an exact finite-sample lower bound on sensitivity. We find that sensitivity is driven by a signal-to-noise ratio in the inference problem, is not reflected in standard errors, does not disappear asymptotically, and is not due to misspecification. While some empirical applications are robust, results of several economics papers can be overturned by removing less than 1% of the sample.
翻译:我们提出一种方法来评估计量经济学分析对去除一小部分数据的影响。 人工检查所有可能的小子集的影响是计算不可行的, 所以我们提供近似值来找到最有影响力的子集。 我们的测量值“ 可能的最大影响受扰动” 自动计算出常见方法, 包括( 但不限于) OLS、 IV、 MLE、 GMM 和变异的 Bayes 。 我们提供近似性能的有限抽样误差界限。 我们以最低的额外费用提供精确的有限类比对敏感度的下限。 我们发现, 敏感度是由判断问题中的信号到噪音比驱动的, 不反映在标准错误中, 不在瞬间消失, 也不是由于误差。 虽然一些经验应用是健全的, 但是通过排除不到1%的样本可以推翻一些经济学论文的结果 。